Bloom Filter 只能处理 =,IN 谓词。
什么是 Bloom Filter?
Bloom Filter 是用于判断某个元素是否在一个集合中的数据结构,优点是空间效率和查询时间都非常高,缺点是有一定的误判率。
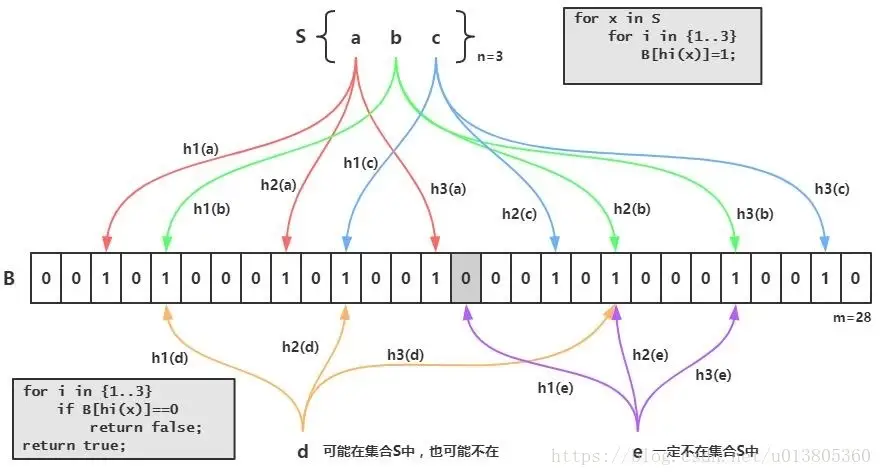

布隆过滤器是由一个Bit数组和多个哈希函数组成。Bit数组初始全部为0,当插入一个元素时,会通过多个Hash函数计算Hash值,并将每个Hash值对应的Bit位置为1。
当我们要判断一个元素是否在集合中时,还是通过相同的多个Hash函数计算Hash值,如果所有Hash值在布隆过滤器里对应的Bit为都是1,则认为该元素存在。由于布隆过滤器的位数有限,以及Hash函数的特性,被判定为存在的元素有可能并不存在,这里存在一定的误判概率。所以,布隆过滤器判定为不存在的元素,是确定不存在的;但布隆过滤器判定为存在的元素,有一定的概率不存在,在这种情况下,需要进行实际查找才能判断元素是否真实存在。
Parquet Bloom Filter 实现
Parquet 使用 Split Block Bloom Filters(SBBF)。
SBBF 把数据划分成了多个 Block,每一个 Block 是 256bits。Block 再划分成 8 个 Word,每个 Word 占用 8bits。一个元素只会存在于一个 Block 中。
SBBF 优点:
- 通过将查询和插入操作限制在单个 Block 中,SBBF 减少了跨缓存行的访问,从而提高了 CPU 缓存命中率和整体性能。
- 由于每个查询或插入只涉及一个 Block,SBBF 可以更好地支持并行处理。不同的查询可以同时访问不同的块,而不会发生冲突。
This Bloom filter is implemented using block-based Bloom filter algorithm from Putze et al.’s “Cache-, Hash- and Space-Efficient Bloom filters”. The basic idea is to hash the item to a tiny Bloom filter which size fit a single cache line or smaller. This implementation sets 8 bits in each tiny Bloom filter. Each tiny Bloom filter is 32 bytes to take advantage of 32-byte SIMD instruction.
查找算法实现
假设查找一个元素 a。首先通过 XxHash,对元素 a 哈希,得到一个 hash: uint64。
hash 将其拆分成两部分,高 32 位用于确定该元素存在哪个 Block 中,低 32 位用于生成 key。
const uint32_t block_index = static_cast<uint32_t>(((hash >> 32) * _block_nums) >> 32);
const uint32_t key = static_cast<uint32_t>(hash);一个 Block 有 8 个 Word,元素 a 已经分别插入这 8 个 Word 中。所以接下来我们需要对每一个 Word 进行查找。
查找每一个 Word 的时候,我们需要将 key 和该 Word 专属的 salt 加盐下。
SSBF 规定如下 8 个 salt,以分别对应 8 个 Word:
// The block-based algorithm needs eight odd SALT values to calculate eight indexes
// of bit to set, one bit in each 32-bit word.
static constexpr uint32_t SALT[8] = {
0x47b6137bU, 0x44974d91U, 0x8824ad5bU, 0xa2b7289dU,
0x705495c7U, 0x2df1424bU, 0x9efc4947U, 0x5c6bfb31U};一个 Word 中查找算法实现:
for (int word_index = 0; word_index < 8; ++word_index) {
// Calculate mask for key in the given bitset.
// ((key * SALT[word_index]) >> 27) 用于生产一个 0~31 的范围,确保能塞在一个 Word 里面
const uint32_t mask = UINT32_C(0x1) << ((key * SALT[word_index]) >> 27);
if (blocks[block_index][word_index] & mask)) {
// 不存在,返回 false
return false;
}
}
// 8 个 Word 检查完毕,存在,返回 true
return true;整一个查找伪代码实现:
bool BlockSplitBloomFilter::FindHash(uint64_t hash) const {
const uint32_t block_index = static_cast<uint32_t>(((hash >> 32) * _block_nums) >> 32);
const uint32_t key = static_cast<uint32_t>(hash);
for (int word_index = 0; word_index < 8; ++word_index) {
const uint32_t mask = UINT32_C(0x1) << ((key * SALT[word_index]) >> 27);
if (blocks[block_index][word_index] & mask)) {
return false;
}
}
return true;
}插入算法实现
这里直接贴 arrow 了,不做具体解释。
void BlockSplitBloomFilter::InsertHashImpl(uint64_t hash) {
const uint32_t bucket_index =
static_cast<uint32_t>(((hash >> 32) * (num_bytes_ / kBytesPerFilterBlock)) >> 32);
const uint32_t key = static_cast<uint32_t>(hash);
uint32_t* bitset32 = reinterpret_cast<uint32_t*>(data_->mutable_data());
for (int i = 0; i < kBitsSetPerBlock; i++) {
// Calculate mask for key in the given bitset.
const uint32_t mask = UINT32_C(0x1) << ((key * SALT[i]) >> 27);
bitset32[bucket_index * kBitsSetPerBlock + i] |= mask;
}
}Parquet Reader上实现
Thrift 定义
/** Block-based algorithm type annotation. **/
struct SplitBlockAlgorithm {}
/** The algorithm used in Bloom filter. **/
union BloomFilterAlgorithm {
/** Block-based Bloom filter. **/
1: SplitBlockAlgorithm BLOCK;
}
/** Hash strategy type annotation. xxHash is an extremely fast non-cryptographic hash
* algorithm. It uses 64 bits version of xxHash.
**/
struct XxHash {}
/**
* The hash function used in Bloom filter. This function takes the hash of a column value
* using plain encoding.
**/
union BloomFilterHash {
/** xxHash Strategy. **/
1: XxHash XXHASH;
}
/**
* The compression used in the Bloom filter.
**/
struct Uncompressed {}
union BloomFilterCompression {
1: Uncompressed UNCOMPRESSED;
}
/**
* Bloom filter header is stored at beginning of Bloom filter data of each column
* and followed by its bitset.
**/
struct BloomFilterPageHeader {
/** The size of bitset in bytes **/
1: required i32 numBytes;
/** The algorithm for setting bits. **/
2: required BloomFilterAlgorithm algorithm;
/** The hash function used for Bloom filter. **/
3: required BloomFilterHash hash;
/** The compression used in the Bloom filter **/
4: required BloomFilterCompression compression;
}
struct ColumnMetaData {
...
/** Byte offset from beginning of file to Bloom filter data. **/
14: optional i64 bloom_filter_offset;
/** Size of Bloom filter data including the serialized header, in bytes.
* Added in 2.10 so readers may not read this field from old files and
* it can be obtained after the BloomFilterHeader has been deserialized.
* Writers should write this field so readers can read the bloom filter
* in a single I/O.
*/
15: optional i32 bloom_filter_length;
}BloomFilter 所在位置由 ColumnMetaData 中的 bloom_filter_offset 确定。当前 Parquet BloomFilter 只支持未压缩+XxHash+SplitBlockAlgorithm 的组合。需要代码里面 check。bloom_filter_length 这个老的 Parquet 文件是没有的,所以我们需要猜测一个大小,把 BloomFilterPageHeader 加载进来,然后再把 BloomFilter 的数据加载进行,需要两次 IO。但是如果 bloom_filter_length 已经被设置过了,那么 1 次 IO 就好了。
每一个 RowGroup 中的每一个列都有一个其专属的 BloomFilter。
BloomFilter 所在的位置不能确定,可能在所有 RowGroup 的前面,也有可能放在 RowGroup 中间。具体以 bloom_filter_offset 为准。
XxHash 函数实现
拷贝 https://github.com/Cyan4973/xxHash/blob/dev/xxhash.h 的实现,注意 license。
读取流程
确认 bloom_filter_offset 是否已经被设置,以此判断是否开启 BloomFilter 过滤。
收集 IO 进行 IO 合并。如果 bloom_filter_length 不存在,那么就没法收集该 IO,只能走 Direct IO。
如果知道 bloom_filter_length 大小,一次 IO 读出来,然后 thrift 反序列化出 BloomFilterPageHeader 没什么好说的。
如果不知道 bloom_filter_length 大小,按照 256 KB 发起一个 guess IO,然后把 BloomFilterPageHeader 反序列化出来。之后再发起一次 IO 把 Data 部分读过来。
中间主要要注意 offset 的检查,其余的没啥特别需要注意的(Trino/Arrow 均已经 check 过了)
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/apache-parquet-bloom-filter
 微信扫一扫
微信扫一扫
评论列表(1条)
细致!