A long time ago in a galaxy far,far away。Lake is Lake,Warehouse is Warehouse。不知道什么时候,搞 Lake 的野心开始膨胀,想要干一部分 Warehouse 的活。但是他们又有自知之明,知道自己不能 100% 取代 Warehouse,所以就发明了一个新词 Lakehouse。

过去很多人会在 Trino、Spark 上面构建 Lake 查询,应付一些性能不敏感的查询。至于性能敏感的查询,则会把目标数据导入到如 Clickhouse、StarRocks、Doris 这样的引擎上。这么做主要一点原因就是 Lake 上的数据都在外部存储上,如 HDFS、S3 等,而它们的访问延时是不确定的,这对于性能敏感的查询来说,是不可接受的。但是这样的做法等于需要维护两套数据,没法做到 single source of truth。
解决外部存储访问延时最好的办法就是 cache,提前把远端数据缓存在本地磁盘,以此消除外部存储访问的不确定性。这样湖上查询就和内表查询没有太大区别了,Lake 也可以凭借 cache,晋升为 Lakehouse。
但是如果 cache 只提供了一些简单的功能,是远无法满足用户的需求,我举几个客户真实的例子:
- 老板第二天 8 点要看报表,得提前把数据拉进 cache,让老板看的顺畅。
- 业务方对某些表有性能要求,OLAP 引擎平台方需要保证这些表尽可能的都在 cache 里面,不然就等着被投诉吧。
- OLAP 引擎平台方承接了全公司的即席查询,他们希望在任何场景下 cache 是一个能够带来正向收益的东西,而不是负优化。
- 一个小白用户希望 cache 开箱即用,一试就灵,不用配置乱七八糟的参数就能秒天秒地。
- 用户的某些表很大,但是查的频率不高。希望把它列入黑名单,不要进行 cache。
可以看出 cache 的上层还得实现一些业务上的逻辑,才能真的让客户用起来。下面我们就借由 Starburst 的 warp speed 来看看如何做好一个 cache 系统。
Warp speed 介绍
Warp speed 是星际迷航里面的术语,指超越光速的速度,Starburst 则是把自己当成企业号了。
Warp speed 主要用于加速 Trino 上面的查询。其有两个版本,一个是在 Starburst Galaxy 上面的,另外一个是在 Starburst Enterprise 上面。
Starburst Galaxy 上面的 warp speed 做的非常简单,用户创建 Accelerated 集群后,就相当于已经开启。之后用户就只管正常查就行了,其他啥都不用管,然后你的查询就会被自动加速了。Starburst Galaxy 隐藏了所有 cache 相关的复杂概念,只会简单的告诉用户每个 SQL 通过 warp speed 加速了多少。用户无需关心 cache 的剩余空间,cache 的淘汰机制,等等。
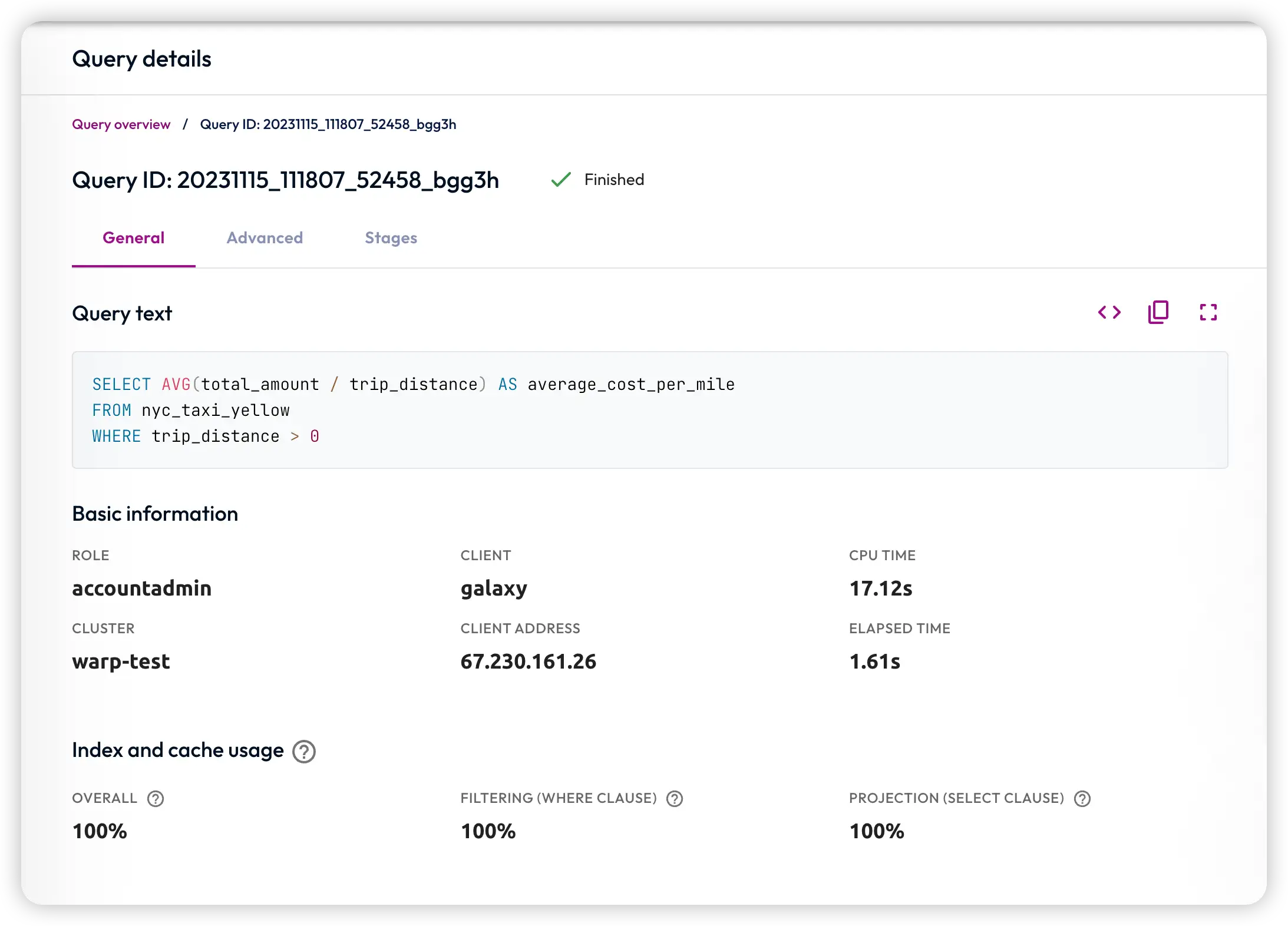
Starburst Enterprise 则在 Starburst Galaxy 的基础上,进一步提供了主动 cache 预热,优先级等功能。用户可以通过 Starburst Enterprise 提供的 REST API,主动预热某些表,某些列。同时用户也可以给某些表设定较高的优先级,确保这些数据不容易被淘汰。也可以给某些表设定最低优先级,等同于将其拉入黑名单,永不进 cache。甚至还可以给 cache 设定 TTL,自行掌管生命周期。
Warp speed 总体实现
Warp speed 通过机器学习算法,自动的分析出用户哪些表、分区,列会被频繁访问,然后自动对其进行预热。预热是异步进行的,不会阻塞正常的查询链路。
预热包含两种手段,一种是建立索引(index),另一种是缓存数据(cache)。
Warp speed 有一个 manager,它独立于 Trino,但是会和 Trino 部署于同一 VPC 网络内。Manager 通过调用 Coordinator 的 REST API 收集所有的历史查询,然后基于机器学习算法,自适应的指导 Trino 的 worker 进行预热。
此外 warp speed 实现了一个新的 connector,以 SPI 插件的形式介入 Trino。目前其只支持 Hive, Iceberg 和 Delta Lake。不过源码里面已经有 Hudi 的代码了,应该马上支持了。
Warp speed 要求机型必须包含 SSD,如果你需要开启弹性 cache 的话,那还需要给 warp speed 配置一个 S3 临时存储桶。
Warp speed 主要包含两个功能模块,分别是 Big Data Index 和 Cache Management:
Big Data Index
列索引,目前支持对 Trino 所有的基础数据类型和 ROW(就是 STRUCT) 里面的子列建立索引,不支持 MAP,ARRAY。Index 能帮助加速 where,aggregation, filters 和 joins 等查询。
索引类型上包含常规索引(B+树这类),Lucene 和 Bloom Filter Index。
Cache Management:
Warp speed 把数据存储划分成三层: Hot,Warm 和 Cold。
Hot: 指 worker 机器上面的 SSD,用于存放 index 和 cache。注意,节点重启,是不会导致 index 和 cache 丢失。
Warm: 这一层只有开启弹性 cache 后才有,指的是你为 warp speed 配置的 S3 临时存储桶。上面也是用于存放 index 和 cache。主要用于 scale 集群的时候快速预热 ,新加入的 worker 直接从 S3 上拉 index 和 cache 就行了。此外 worker idle 的时候,也无需继续保留实例,反正预热的数据已经持久化在 S3 上面。总之当一个节点需要预热的时候,它会先尝试从 S3 上面拉取,如果有的话,就直接用了,不再额外执行预热操作。
Cold:指你存储在 S3/HDFS 上的源数据。
Warp speed 的 cache 能够保证你不会读取到过期的数据。Cache key 的生成算法很简单,hash(file_name + file_size + modification_time) 就行了。file_name,file_size 和 modification_time 均属于文件的 metadata,各类文件系统都有提供相应的 API 获取。
查询加速引擎(Query Acceleration Engine)
Warp speed 引入了 Query Acceleration Engine,负责管理 index 和 cache。
Query Acceleration Engine 会自己收集用户的 SQL,通过机器学习算法,分析出哪些表,哪些列需要预热。然后 Query Acceleration Engine 基于当前 Trino 的 workload,自动发送 Acceleration Instructions 到每个 worker 上面,让其执行预热操作。
当一个查询命中未缓存的列时,Query Acceleration Engine 会发起一个 default acceleration。它的优先级是最低的,只要空间足够,就会一直尽可能的填充。Default acceleration 不需要通过 Query Acceleration Engine 的机器学习算法分析,会直接发起。
SELECT * FROM的 sql 不会触发 default acceleration,因为默认这种 SQL 只是用于探查表数据,而不是真实的查询。
Query Acceleration Engine 通过机器学习分析完实时收集的 Query 后,它会发起 Acceleration Instructions,其缓存优先级是大于 default acceleration 的。
Acceleration Instructions
Acceleration Instructions 分为两种,分别是 Cache Instructions 和 Indexing Instructions。
Cache Instructions:根据数据的访问频率,把频繁访问的数据缓存在 worker 的 ssd 上面,按列存储。
Indexing Instructions:根据列的具体类型和其 selectivity,自适应的建立合适的 index 索引。
Selectivity 的计算比较简单,以 ScanNode 为例。 Selectivity = OutputRows * RowSize / InputRows * RowSize
Acceleration Instructions 可以由 Query Acceleration Engine 自动发起,也可以人为通过 REST API 手动触发。
你可以在 Control Center 查询管理所有的 Acceleration Instructions。
Acceleration Instruction 相关属性
一条 Acceleration Instruction 包含如下属性:
- 目标 Column
- 目标 Table
- 目标 Database
- 目标 Catalog
- 目标 Partition
- Instruction 类型,包含:Index,Data,Lucene,Bloom High,Bloom Medium 和 Bloom Low。
- 优先级(即是指在 cache 中的优先级,也是指预热任务执行的优先级),分为如下优先级:
- Always,强制发起预热任务,且数据不会被淘汰(只有用户可以定义)
- High(只有用户和 Query Acceleration Engine 可以定义)
- Medium(只有用户和 Query Acceleration Engine 可以定义)
- Low(只有用户和 Query Acceleration Engine 可以定义)
- Never,相当于黑名单,禁止对某些表进行缓存(只有用户可以定义)
用户发起的 instructions 优先级可以覆盖 Query Acceleration Engine 发起的 instructions 优先级,但是 Query Acceleration Engine 不能覆写用户 instructions 的优先级。
- TTL,指定该 instruction 关联的 index 和 cache 的过期时间。使用 ISO-8601 表示。
最佳实践:如果你想某些表一定要被加速,可以设置 Always 优先级(前提是你的空间足够)。同样想要禁止加速某些表,可以设置 Never 优先级。
空间管理
当集群剩余空间容量到达上限 warmup-demoter.max-usage-threshold-percentage,那么系统会对集群预热的数据进行清理。一直清理,直到满足 warmup-demoter.max-cleanup-threshold-percentage 阈值。
清理规则如下:
- 清理所有 TTL 已经过期的数据。
- 清理最低优先级的数据。
可以看出,warp speed 并不是采用简单的 LRU 淘汰方式,而是触发阈值后,后台一次性清理。
Text Analatics(Lucene Index)
Warp speed 使用 Apache Lucene 的 KeywordAnalyzer 加速 text 文本分析查询。
Lucene indexing 推荐加速如下场景:
- Like 谓词,prefix(如
START_WITH()函数),suffix 查询(如END_WITH()函数)。但是 Lucene Index 不支持含有子表达式的情况,如:select from table where starts_with(some_nested_method(col1), 'aaa')。 regexp_like()表达式。- 对于 string 列的范围查询,比如
date_string>='yyyy-mm-dd'这种。
自适应预热代码实现
这一节大家就当玩笑看看就行了,毕竟人家也没开源。
Acceleration Engine 的自适应预热由 Brain 模块负责,这部分代码由 python 编写。Brain 分为 Collector,Extractor 和 Analyzer 三个部分组成:
Collector
通过 Trino coordinator 的 REST API 获取每个 query 的 json profile,用 gzip 压缩后,上传到 S3 上面。按照 SQL 的结束时间,上传到 Year/Month/Day/Hour/Minute 这样结构的目录里面。
Extractor
从 S3 上面拉取 Collector 收集的 json profile,逐个分析,分析结果以 ORC 格式导出,再存回 S3。
存储的 ORC schema 如下:
etag: "string"
query_id: "string"
element_id: "string" # 表名
partition_id: "string" # 分区值
element_type: "string" # 列类型
warmup_type: "int" # warmup 类型,有 WARMUP_BASIC,WARMUP_TEXT, WARMUP_DATA
input_bytes: "bigint" # 输入 bytes = input_rows * col_size
output_bytes: "bigint" # 输出 bytes = ouput_rows * col_size
workload_priority: "int" # 不清楚一个 query_id 会往 ORC 里面写入多行,比如这个 query 涉及到一个表中的 5 列,10 个分区,那么这里就会插入 50(5×10) 行 orc 数据。
warmup_type 的判断逻辑很简单:
- 如果某一列是 string 且存在 like、start_with 等这类字符串谓词,那么其
warmup_type是 WARMUP_TEXT。 - 如果某一列存在普通谓词,但又不符合 WARMUP_TEXT 的条件,那么其就是 WARMUP_BASIC。后续根据其谓词的 selectivity,选择合适的 index 类型。
- 如果某一列不存在谓词,那么就是 WARMUP_DATA,只缓存列数据。
给大家贴一段 Extractor 处理 query json profile 的代码实现:
def extract_rows(j: dict, catalogs: str, workload_rows: list, workloads_dict: dict, etag: str):
output_stage = j.get("outputStage")
if output_stage is None:
return
query_id = j["queryId"]
nodes = {n["id"]: n for n in plan.iter_nodes(output_stage)}
user = j["session"]["user"]
sql = j["query"]
tables = dict(plan.iter_tables(output_stage))
tables_names = [table['tableName'] for table in tables.values()]
partitions_map = get_partitions_map(j["inputs"])
workload_priority=get_workload_priority(workload_rows, workloads_dict, user, tables_names, sql)
for op in plan.iter_operators(j):
node = nodes[op["planNodeId"]]
filter_node = scan_node = None
if node["@type"] == "project":
node = node["source"]
if node["@type"] == "filter":
filter_node = node
node = node["source"]
assert node["@type"] == "tablescan"
scan_node = node
node = None
table = tables[scan_node["id"]]
table_name = table["tableName"]
if any(table_name.startswith(p) for p in PREFIXES_TO_SKIP):
continue
predicate = filter_node.get("predicate") if filter_node else ""
lucene = set()
col_domains = scan_node.get("table", {}).get("connectorHandle", {}).get("stringMatchersConstraint", {}).get("columnDomains", None)
if col_domains is not None:
for j in col_domains:
string_matchers = j['domain']['values']['stringMatchers']
if string_matchers['likePatterns'] or string_matchers['regexpLikePatterns']:
lucene.add(j['column']['baseColumnName'])
for sym, col in scan_node["assignments"].items():
col_name = get_keys(col, "columnName", "baseColumnName")
element_id = f'{table["tableName"]}.{col_name}'
if not re.search(element_id.split('.')[0], catalogs):
continue
column_type = col.get("columnType")
if column_type == "PARTITION_KEY":
continue
input_rows = op["inputPositions"] + get_skipped_rows(op)
output_rows = op["outputPositions"]
data_type = get_keys(col, "type", "baseType")
col_size = plan.get_type_size(data_type)
# TODO: explain the logic
if f'"{sym}"' in predicate:
if col_name in lucene and col_size >= 9: # Lucene rule should not be created for string with less than 9 chars
warmup_type = schema.WARMUP_TEXT
else:
warmup_type = schema.WARMUP_BASIC
else:
warmup_type = schema.WARMUP_DATA
partitions = partitions_map.get(table["tableName"], [None])
num_partitions = len(partitions)
for partition_id in partitions:
yield schema.Row(
etag=etag,
query_id=query_id,
element_id=element_id,
partition_id=partition_id,
element_type=data_type,
warmup_type=warmup_type,
input_bytes=input_rows*col_size // num_partitions,
output_bytes=output_rows*col_size // num_partitions,
workload_priority=workload_priority)Analyzer
读取 Extractor 产生的 ORC 文件,通过基于规则的算法(其实没有机器学习算法),分析出要创建哪些 acceleration instructions。
这里我就要插一嘴了,你 PPT 里面吹得那么牛,说有机器学习算法,但是我看源码,并没有啊,纯粹就是基于权重的加加减减罢了。
- 先分析 ORC 文件,创建出一系列的 warm up rules。
- 合并相邻 partition 的 rule,以减少 rule 的数量,避免过多的 rule 造成较大的预热开销。
- 读取用户自定义的 warmup rule,和系统自动生成的 rule 进行合并。
- 根据合并后的 warmup rule,生成 acceleration instructions,发送到 worker 执行 。
算法实现这块比较复杂,没太看懂,我们也不一定要按照它的实现来。
总的来说,就是算法一定要考虑上分区时间。举一个简单的例子,比如今天是 4 号,根据过往的历史数据,发现 1 号,2 号,3 号的访问频率都很高,那么意味着今天 4 号的访问频率大概率也会很高,这里需要用一个算法预判这种行为。
Analyzer 引入了一个有趣的概念,叫 query age,也就是 query 发起时间 - 查询分区的时间,然后你可以基于 query age 做一些基于权重的算法。
关于 warp speed 的一点思考
总的来说 warp speed 就是通过收集用户的历史查询的 json profile,提取出关键信息,然后通过基于规则的算法,自适应的预热,以此尽可能的减少用户的心智负担。另外 warp speed 通过一个临时的 S3 存储桶,实现了弹性 cache。
我强烈建议大伙去体验下 Starburst Galaxy 的 warp speed,你会感觉它就是 Lake 届的 Apple,东西做的简单易上手,一下子就有让人充值 credit 的欲望。
在如今降本增效的背景上,性能可能没有那么重要。你快个 1s,我慢个 2s 追究起来真的没有太大意义,易用性才是王道。客户采购你的产品,肯定是希望你能降低他们的成本,而不是还要额外招一个 team 来运维你那复杂的产品。
所以一个好的数据库根本不应该有啥调优指南,也不应该出什么书。MySQL 能有那么多书,那么多八股,是不是也侧面说明了它做的很难用?
拿我文章开头举的用户需求为例子,估计有人会发明 pin/unpin 的语法来管理 cache 的淘汰 。然后又提供一些语法来管理 cache 的优先级,黑名单等等。之后文档里面又会引入一些新的 cache 概念,然后成功的让用户在 disk cache,query cache,page cache 等各种 cache 概念里面凌乱。Profile 里面估计又会整一堆 cache 的指标,然后除了自己公司的员工能看懂之外,没人看得懂。
你可能会说,管 OLAP 平台的人会这么菜吗?
就这么说吧,牛逼的人(如各种互联网大厂),那绝对是白嫖怪,人家才不会花钱买你的服务。真正买你服务的金主爸爸,都是那些水平不咋地,只想掏完钱什么都不管的人。在他们的采购标准中,一个简单易用的 UI 界面都会是一个重要的加分项。
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/cache-automatic-warmup-starburst-warp-speed
 微信扫一扫
微信扫一扫