本文只写给自己,所以比较粗糙。
调度衡量指标
Turnaround time
Turnaround time = 任务完成时间-任务到达时间
$$
T_{turnaround} = T_{completion} – T_{arrival}
$$
Response time
如果通过 turnaround time 来衡量调度的算法,STCF 算法是最好的。
我们定义 response time 为任务到达系统至第一次被调度的时间。
$$
T_{response}=T_{firsturn}-T_{arrival}
$$

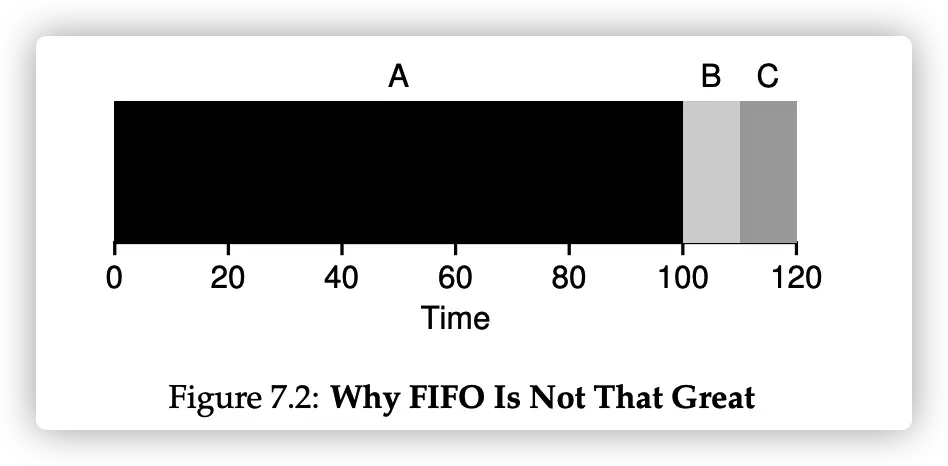
First In, First Out (First Come, First Served)
没什么好说的,先来先服务。
缺点:
缺点很明显,如果第一个任务耗时很久,后面即使再短的任务,也要等待很久才能排到队。
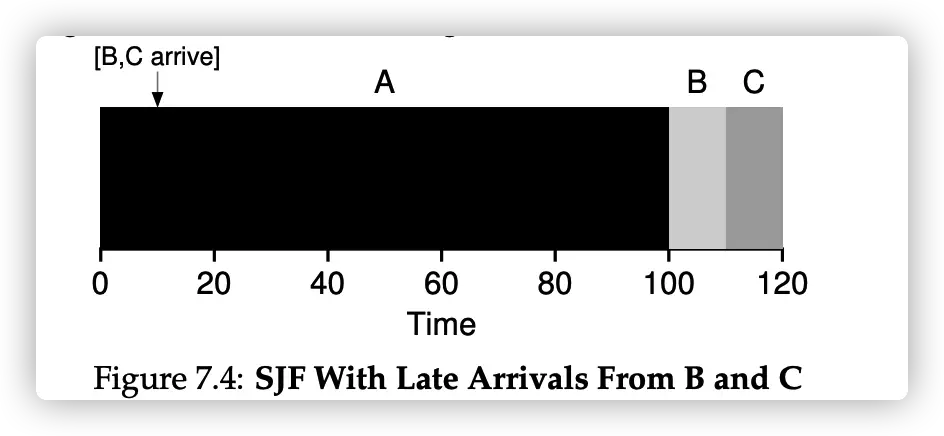
Shortes Job First
最短任务优先。
缺点:
- 在非抢占(non-preemptive)的操作系统中,如下情形,就很蛋疼,B 和 C 同样很晚才能成功执行。
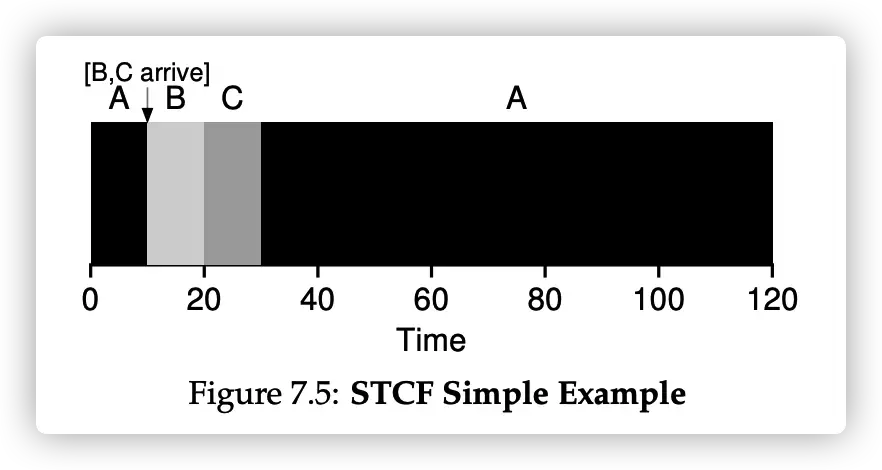
- 容易饿死 starve 长任务,如果耗时短的任务不断来了,那耗时长的任务永远无法执行。 Shortest Time-to-Completion First
和最短任务优先差不多,不过前提是操作系统需要支持抢占。
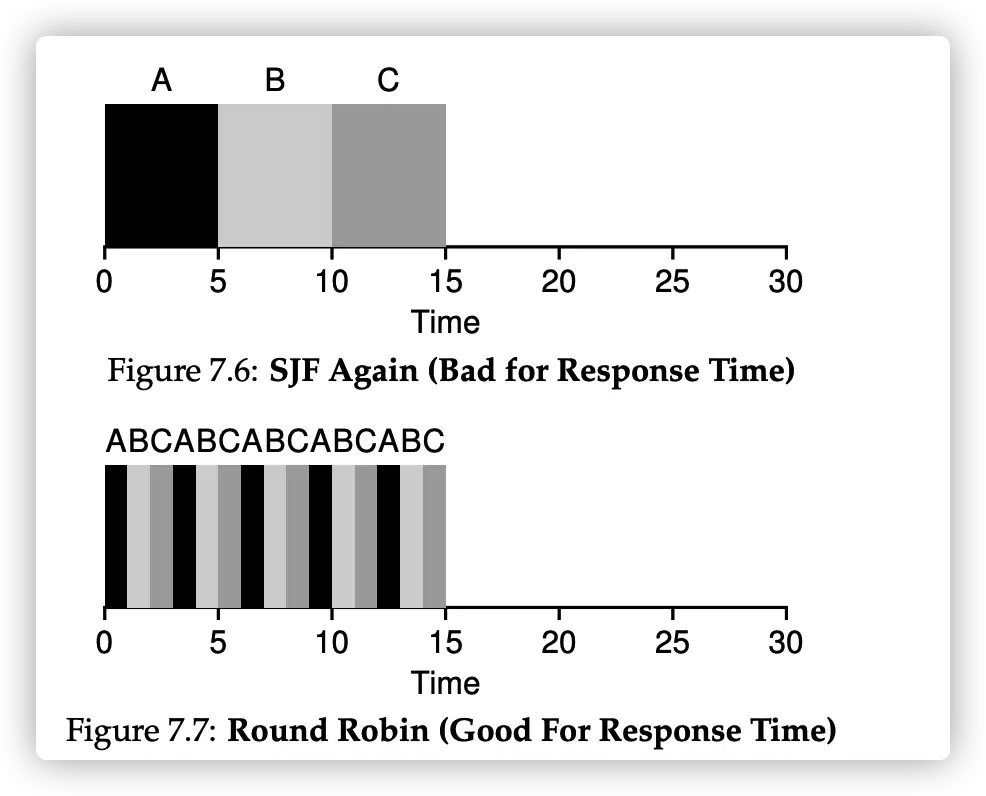
Round Robin
Round Robin 将任务根据 time slice 划分,一个 time slice 的长度通常为 timer-interrupt peorid 的倍数。
Round Robin 能够使得 response time 最佳,前提是 time slice 的长度合理。Time slice 过短,使得 context switching 过于频繁,消耗大量的系统资源。但是,这种调度算法会使得 turnaround time 时间过长,甚至不如 FIFO 算法。
The Multi-Level Feedback Queue
MLFQ 主要解决两个问题:
- 尽可能的优化 turnaround time,像 Short Job First 算法一样尽可能的缩小 turnaround time。但是我们不可能是先知,知道一个应用会执行多久,所以用 MLFQ 解决这个问题(learn from history)。
- 我们也要尽可能的优化 response time,这样在一些 interactive 的系统中能极大的提升用户体验。但是像 Round Robin 一样的算法,会极大的恶化 turnaround time。
综上,我们需要一个 balance。
MLFQ 拥有多个不同的 Queue,每个 Queue 拥有不同的 priority level。一个 queue 可以同时运行多个任务,一个 queue 中多个任务根据 round robin 方法运行。
Rules:
- Rule 1 if Priority(A) > Priority(B) ,run A, not B。
- Rule 2 if Priority(A) = Priority(B), run A & B in Round Robin。
- Rule 3 当一个任务进入系统,默认在优先级最高的队列中执行。
- Rule 4 一个任务在运行中时,如果他在一个 time slice 中放弃了 CPU,那它保持原有优先级队列,否则会被降一级。(如果一个任务用完了预分配给它的时间,那也会被强制降一级,即使它每次都在一个 time slice 结束前放弃了 CPU。此举主要为了防止有些恶意应用估计频繁放弃CPU,以此来一直占用CPU使用。)
- Rule 5 通过一段时间 $S$ ,将所有任务移到最高优先级的队列。(这么做是为了防止一些 long-running 的任务被那些频繁放弃 CPU 任务饿死,分配不到 CPU资源)
MLFQ 最大的问题就是太多参数,需要经验进行设置。例如 time slice 大小,$S$ 的长度等等。
Solaris 使用动态 time slice,优先级高队列的 time slice 小,优先级低队列的 time slice 大。Free BSD 通过数学公式来计算一个应用的优先级(基于过去 CPU 占用情况等信息)。
Lottery scheduling
每个 job 拥有一定数量的 ticket,然后抽奖。例如 A 有 75 个 ticket,B 有 25个 ticket,那么 A 被安排到 CPU 的概率为 75%,B 为 25%。
缺点:
这种随机不能带来真正意义上的公平,只有 job 够长,才足够 fairness。
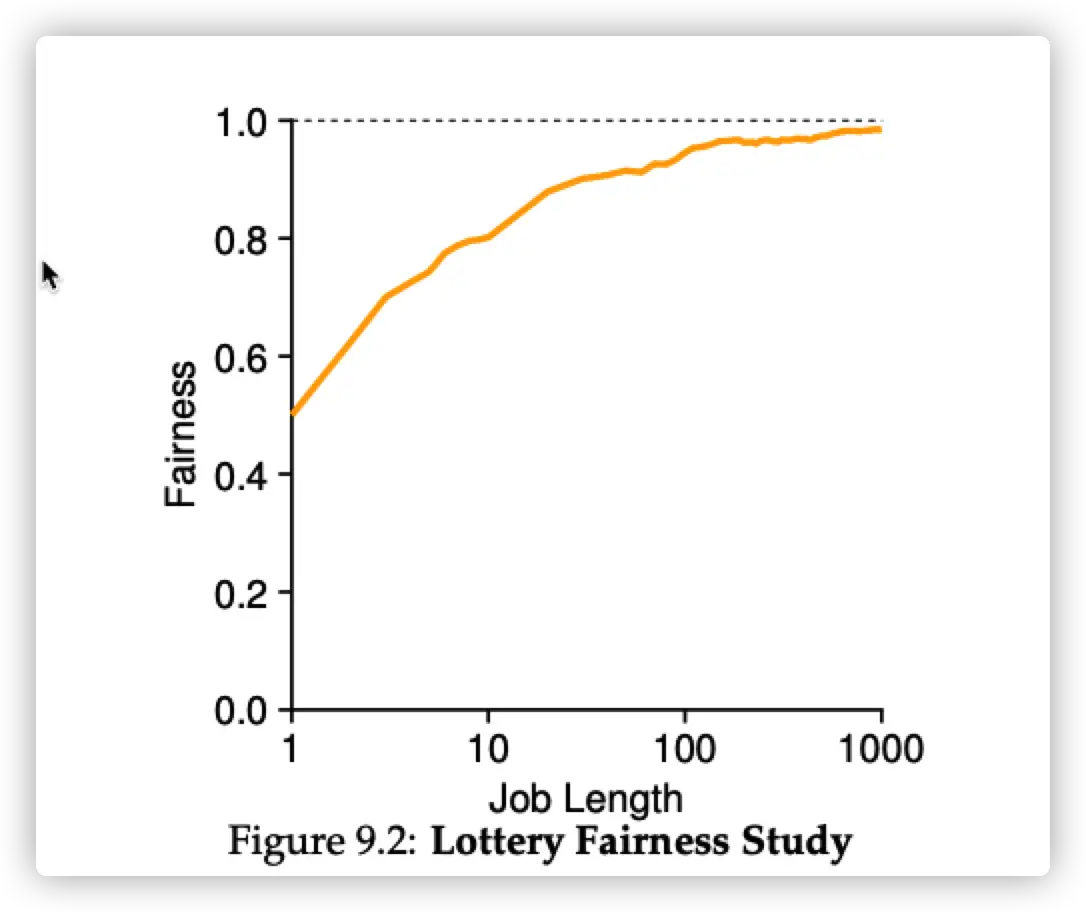
如何分配 ticket 也是一个问题,总不能每个 job 都需要用户指定 ticket,太麻烦了。
Stride Scheduling
每一个 job 有一个 stride。Stride 计算方法是 (自己定的一个数 / ticket)。每一个 job 有一个 counter,每一次运行选择所有 job 中 counter 最小的。当一个 job 执行完成后,其 counter = counter + stride 。
例如 ticket 为:A -100, B-50, C-250。然后自己定一个数,10000 除以 ticket,分别得到 stride:A – 100,B – 200,C – 40。
- 所有 job 的 counter 均为 0,在 A,B,C 中随机选择。假设选择 A,A 运行完成后,A 的 counter 变成 100。
- B 和 C 的 counter 均为 0,再次随机选择,假设选 B,其后 B 的 counter 变为 200。
- C 的 counter 为 0,最小,执行 C,后面以此类推。
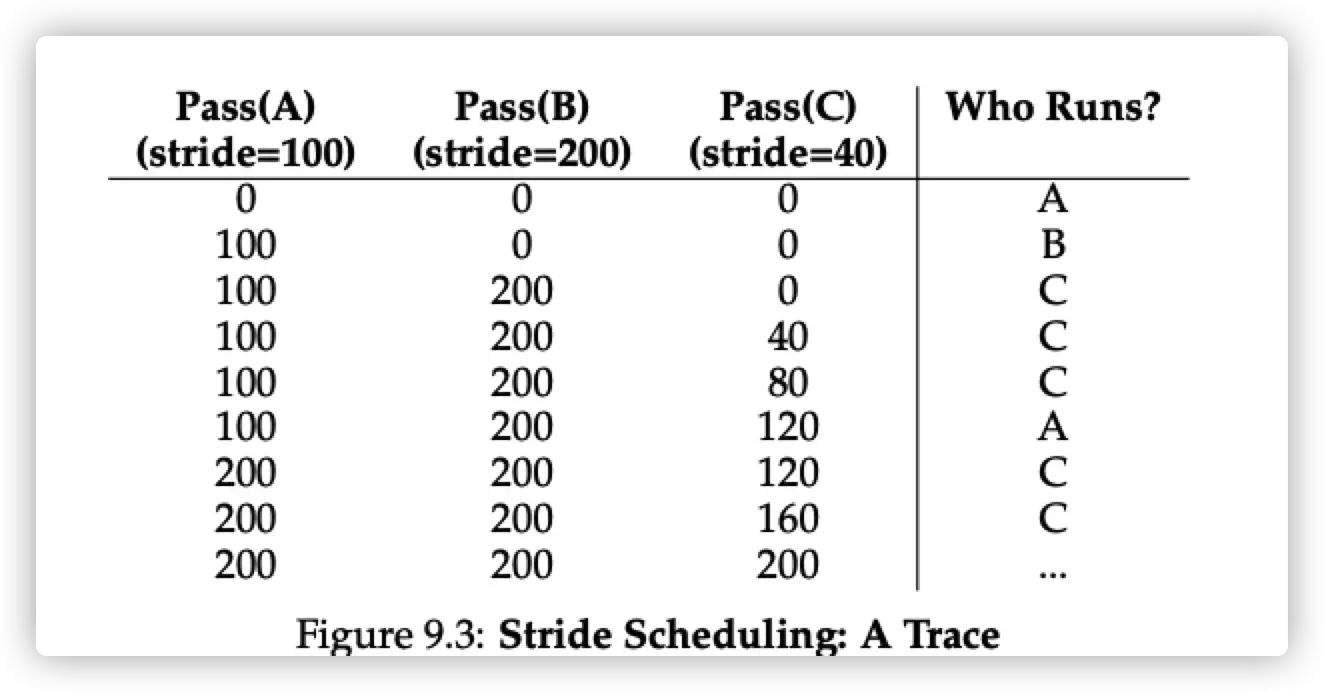
可以看到 C 运行 5次,A 两次, B 以此,严格对应 ticket 的数量,取消了 randomness。
既然 stride scheduling 能够避免 randomness,为什么不直接用 stride scheduling,要 lottery scheduling 干嘛。
lottery scheduling 有一个优点,no global state。假设 A B C 在运行的过程中,来了一个 D,那么 D 的counter应该是多少,如果为 0,那么后面 D 不就是可以独占 CPU 了。而且 lottery scheduling 不需要保存每个 job 的 counter。
The Linux Completely Fair Scheduler
CFS 期望达到两个目标,一个是完全的公平,另一个则是花费尽可能少的时间做出调度决策。
在 CFS 中,每一个 job 都有一个 virtual runtime(vruntime)。当一个 job 运行时,它的 vruntime 会按照 real time 按照一定的比例(取决于 weight)增加。每一次 scheduling,选择 vruntime 最小的 job。
CFS 每一次 scheduling 的间隔,由几个参数控制。
sched_latency 是一个参数,每个 job 的 time slice 的长度由 sched_latency 除以当前运行的 job 数量。例如 sched_latency 为 48 ms,当前有 4 个 job 运行,那么 time slice 为 12 ms。
下图可以看到,起初有 4 个 job,time slice 小。后面随着 C 和 D 的完成,time slice 变大。
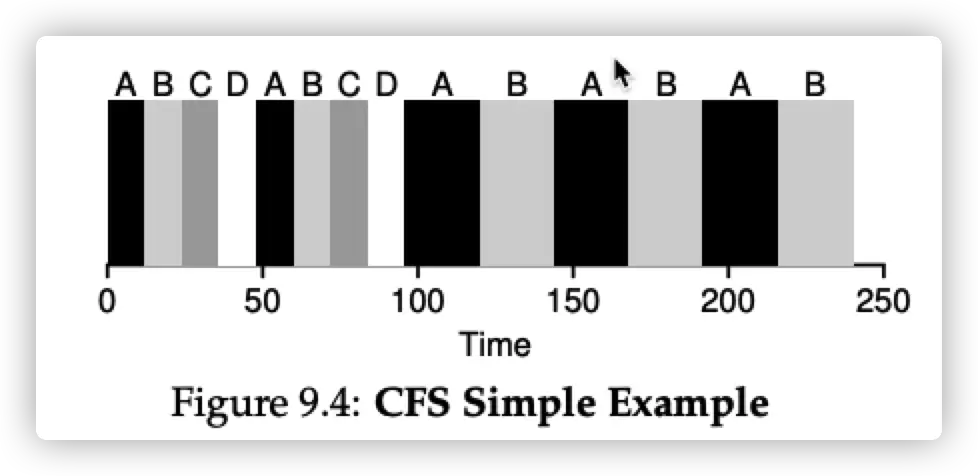
同时,CFS 设置了 min_granularity,用于解决当同时运行的 job 过多,使得 time slice 太小,使得 scheduler 频繁的进行线程切换,得不偿失。
CFS 同样实现了 weighting(Niceness)
Linux 的 nice 指令提供了不同 nice 对应的 weight:
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};一个任务的 time_slice 计算公式如下:
$$
TimeSlice_k=\frac{weight_k}{\sum^{n-1}_{i=0}weight_i} \cdot SchedLatency
$$
同时其 vruntime 增加时间也应该改一下:
$$
vruntime_i=vruntime_i+\frac{weight_0}{weight_i} \cdot runtime_i
$$
其中 $weight_0$ 为 default weight,为 1024。
CFS 采用红黑树来加速查找下一个运行的 job。CFS 不会把所有 process 放在红黑树里面,只有存放 running job。那种 sleep 的等会移除红黑树。
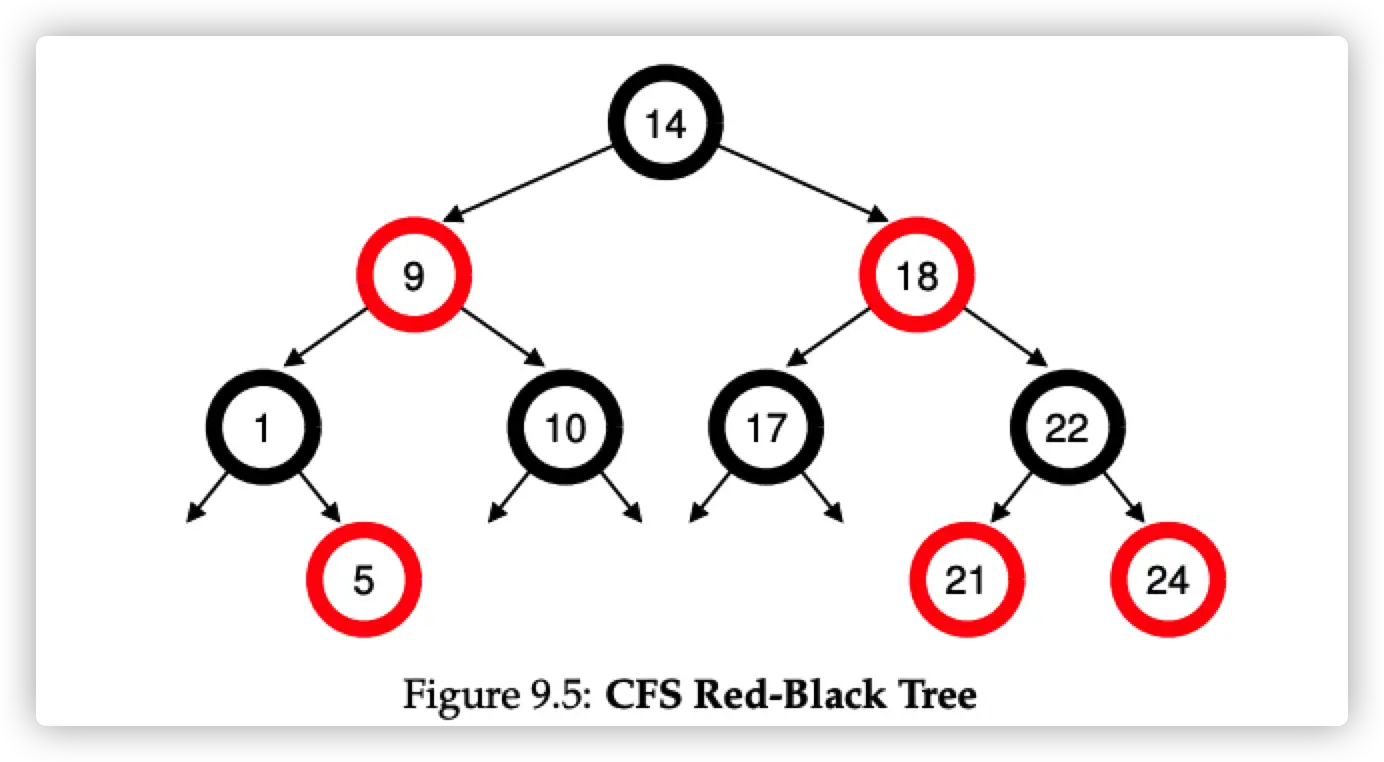
同样为了防止新任务进来,其 vruntime 最小,使得独占整个 CPU。当一个新的任务进来,其 vruntime 为整个红黑树中 vruntime 最小的值。(这种方法可以同样解决,例如 A,B同时运行,然后 B sleep 了一段时间,然后唤醒。因为 B 的 vruntime 肯定最小,然后独占整个 CPU)。
Multiprocessor Scheduling
Single-Queue Multiprocessor Scheduling
就一个队列,哪个 CPU 有空发哪里。基于 single-CPU 上面的调度算法改造,同时 pick n 个 任务。(比如每次同时选择 2 个 best job 分配到 2 个 CPU 上面)。
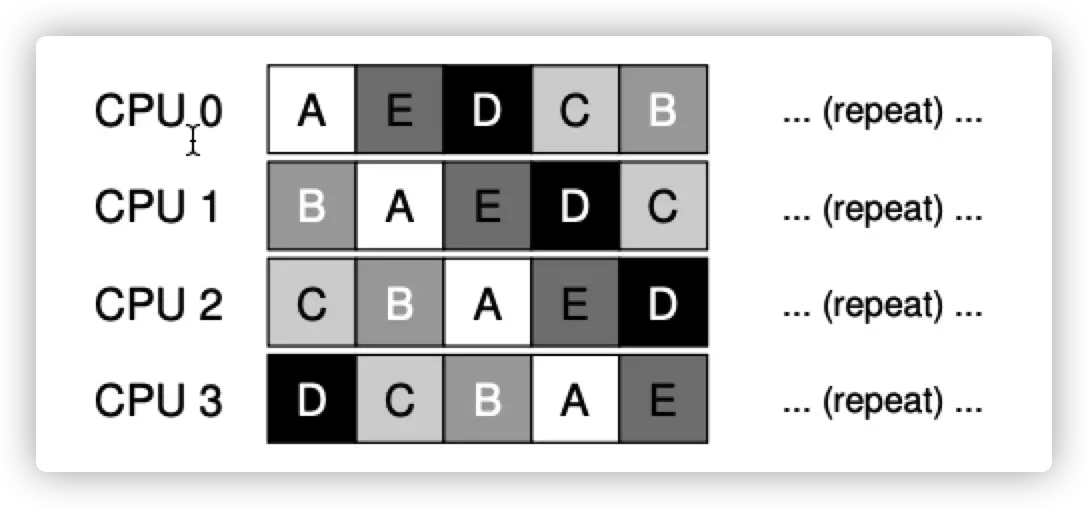
一个任务会被分配到不同的 CPU 上面,需要 lock,缺乏 scalability。同时也缺少 cache affinity(每个 CPU 有自己的 cache)。
当然有些 SQMS 会尽可能的提升 cache affinity。调整结果如下:
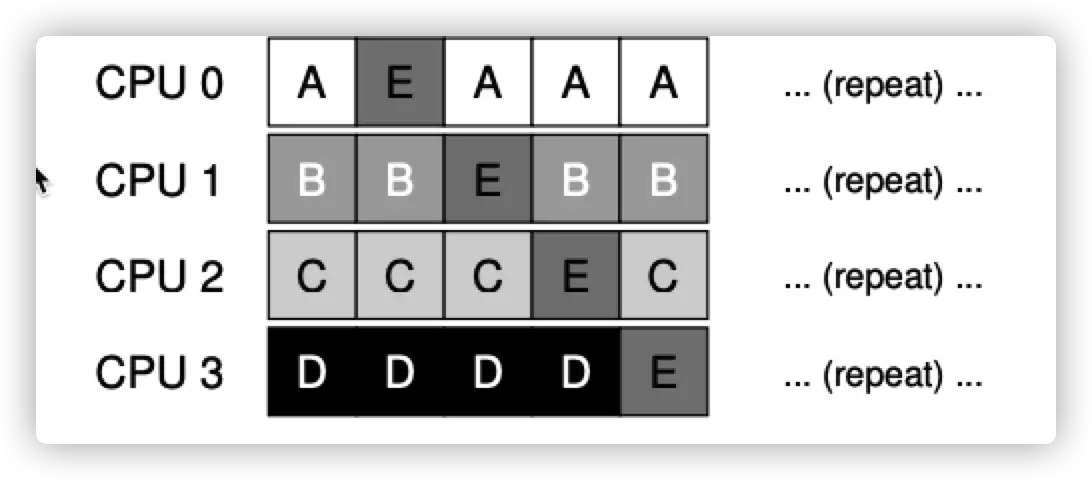
Multi-Queue Scheduling
就是每个 CPU 对应一个 queue,但是随之而来的问题就是可能会导致不同 queue 之间的 imbalance。
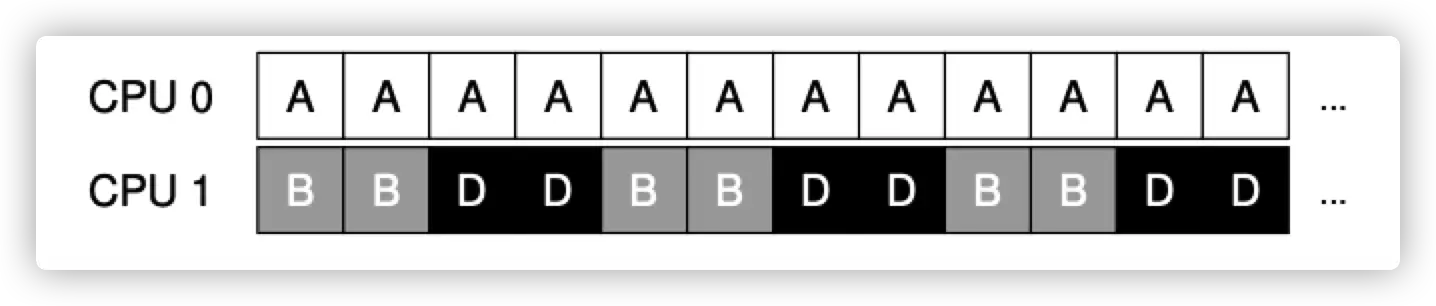
解决办法就是 mirgration,哪里空搬哪里。或者 steal,当一个 queue 很空的时候,从繁忙的 queue steal 一些任务。
但是并没有那么好实现,需要 banlance。何时 steal,steal 的频率,等等,都是 a black art。
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/cpu-scheduling-policies
 微信扫一扫
微信扫一扫