这一篇文章主要参照 CMU 15-445 Project 3 的 Query Execution 章节,特此记录。
本文所有的 Cost 均为 IO Cost。
数据库操作主要包含如下三大类:
- Access:Sequential Scan
- Modifications: Insert, Update, Delete
- Miscellaneous:Nested Loop Join, Hash Join, Aggregation, Limit, Distinct
Access 和 Modifications 没什么好说的,无非是通过 B+ 树进行增删查改工作,这里不说了。
External Merge Sort
排序操作是数据库很多复杂操作的基石,显式的如 ORDER BY 调用,它会直接根据指定的字段进行排序。而一些复杂操作如 JOIN、GROUP BY 等,会需要先对数据进行排序处理,然后再进行相应的处理。
如果所有的数据都可以放在内存里面,我们可以直接使用快排处理,但是这显然不可能,所以我们需要 External Merge Sort(外部归并排序)。
我们先假设数据总量有$N$ 个 page, 数据库提供 $B$ 个 buffer page。
外部归并排序分为两阶段:
阶段一:Sorting
PASS #0:每一次读取 $B$ 个 page 数据,排序,输出文件。总共需要 $\lceil N/B \rceil$ 轮,每一次输出的一个文件称为一个 RUN,故共生成 $\lceil N/B \rceil$个 RUN。
每一轮处理叫做一个 pass。
阶段二:Merging
数据库提供 $B$ 个 buffer page,其中 $B-1$ 个 page 用于输入 RUN 数据,剩余的 1 个 page 用于输出到磁盘。
PASS #1
每次选择 $B-1$ 个RUN,合并输出成一个新 RUN。循环此操作,直到把 PASS #0 生成的 RUN 全部合并完成。
PASS #2
同上继续循环选择 $B-1$ 个 RUN 合并输出。
…
PASS #N
当剩余的 RUN 数量小于等于 $B-1$ 时,则是最后一次合并了,因为此时所有的 RUN 都可以被一次性合并。
$$
Number\ Of\ Passes=1+\lceil log_{B-1}\lceil\frac{N}{B}\rceil \rceil
$$
加 1 是因为要算上第一阶段 PASS #0 创建 RUN。
$$
Total\ I/O\ Cost=2N\cdot (Number\ of\ passes)
$$
$2N$ 是因为把一轮都会读取一次全部数据 $N$,一读一写,两次。
下图是 2-way external merge sort 的例子。
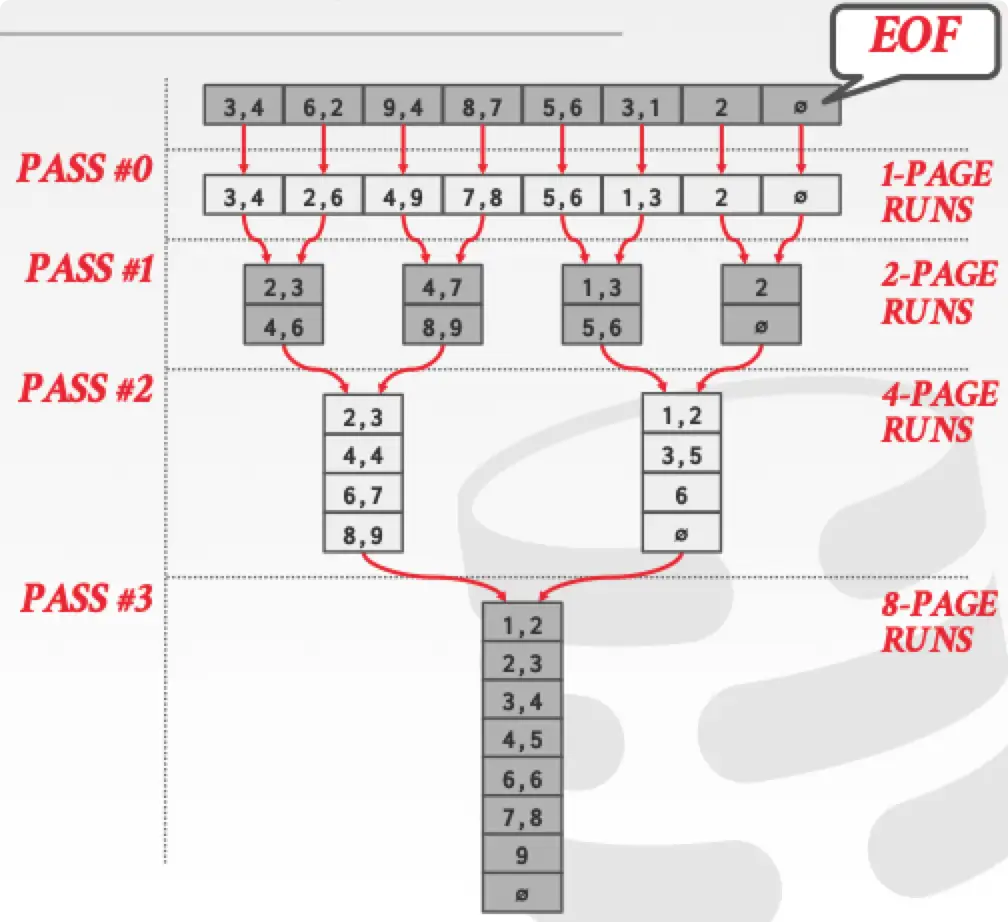

可以看到归并排序最少只需要 3 个 buffer page 即可实现。
如果内存充足,可以在处理当前 RUN 的时候,提前预读下一个 RUN 的数据到内存中。
B+ Tree Sort
如果我们需要排序的列正好存在索引,我们可以利用 B+ 树的性质进行排序。
分 Clustered Index 和 Non-Clustered Index 两种情况考虑。
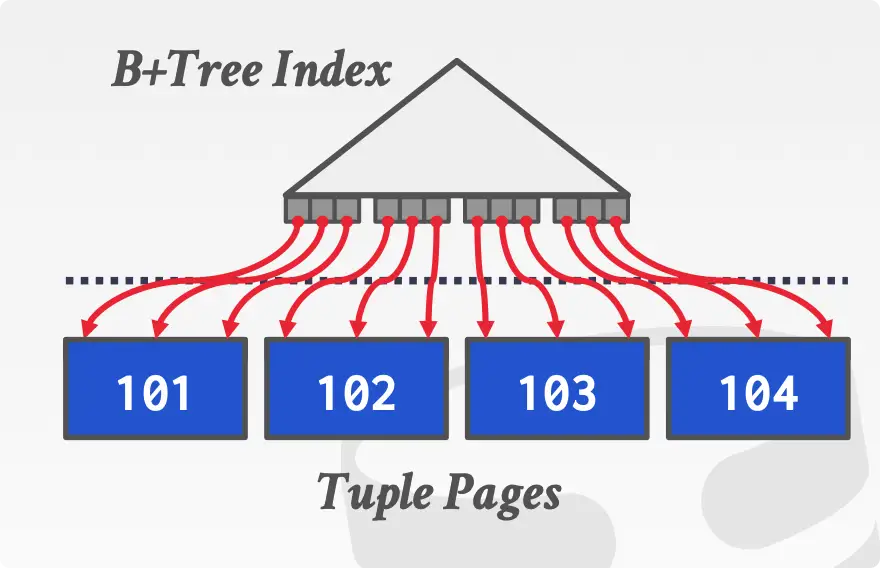
- Clustered Index:索引和 tuple 存放在一起,通过 B+ 树的性质,直接遍历即可,效果最好。
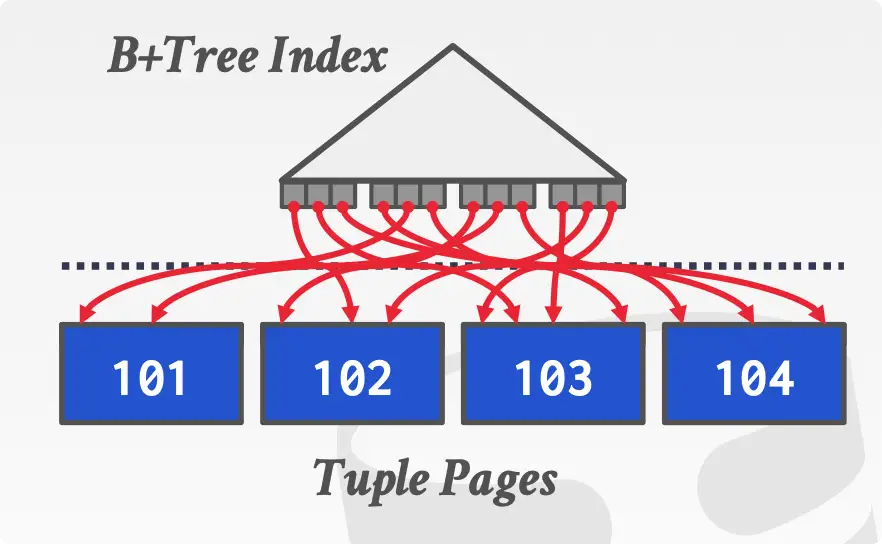
- Non-Clustered Index:索引和 tuple 分开存放,索引存放着指向 tuple 的指针。虽然索引有序,但是 tuple 不是有序,会涉及大量随机 IO,不采用此方法。
Aggregation
Aggregation 操作包含 ORDER BY,GROUP BY,DISTINCT 等。
可以通过 Sort 和 Hash 两种方法处理。
对于 GROUP BY 和 DISTINCT ,使用 Hash 是一种更好的方法,因为不需要事先排序。Hash Table 可以使用 Extendible Hash Table,当内存不够时,其会自动 spill page 到 disk 上。
当 key 很多,一个 Hash Table 放不下时,我们可以采取多次 Hash 的策略。第一次 Hash 生成多个 partition,然后再单独针对每一个 partition 再一次进行 Hash。
GROUPY BY 在 Hash Table 中的保存格式是 Group Key->Running Val 。每次插入一个 tuple 时,如果存在对应的 Group Key,则更新 Running Val,根据你的聚合函数处理,比如 sum() 就直接加上去。如果不存在对应的 Group Key,则直接插入 Hash Table。
Running Val 根据你的聚合函数种类存储不同的格式:

Join
- Early Materialization:在 join 的时候直接把 tuple 连接在一起。好处是后期不用回数据库读取 tuple,缺点是后面的 SELECT 可能只需要几个字段,而你的 tuple 里面可能会包含多余不需要的字段。
- Late Materialization:Join 的时候只拷贝 join keys 对应的 record ID。后期再根据 SELECT 的语句选择性加载 tuple,列式存储的数据库采用这种方法很划算。缺点是后面读取的时候就是随机 IO 了,因为 record ID 指向的数据大概率已经不是连续了。(当然这在按列式存储的数据库里没问题。)
Join 种类
- Natural Join:将表里面列名相同,且值相同的 tuple 连接在一起,输出的时候不会重复输出相同的列名。
SELECT * FROM student NATURAL JOIN takes;。 - Join Conditions:Natural Join 是自动连接两个列名相同的 tuple,但是如果我想连接自己指定两个列名,就要使用 ON 语法。
SELECT * FROM student JOIN takes ON student.ID = takes.ID;。这种 Join 学术上也叫 equi-join。 - Outer Joins:这就是我们传统数据库里面接触的 join。有 left outer join(left join),right outer join(right join) 和 full outer join(full join)。传统 SQL 语法里面一般都直接省略了 outer 关键字。
为了和 outer join 对应,普通的 join 叫 inner join,natural join 属于 join 的子集,故 natural join 也叫 natural inner join。
Inner join … on …:

Left join … on …:
Right join … on …:
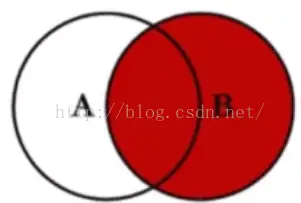
Full join … on …:
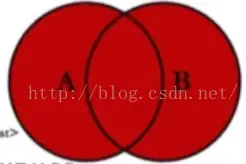
Nested Loop Join
Nested loop join 就是用一种很传统的思想,两个 for 循环来实现 join。
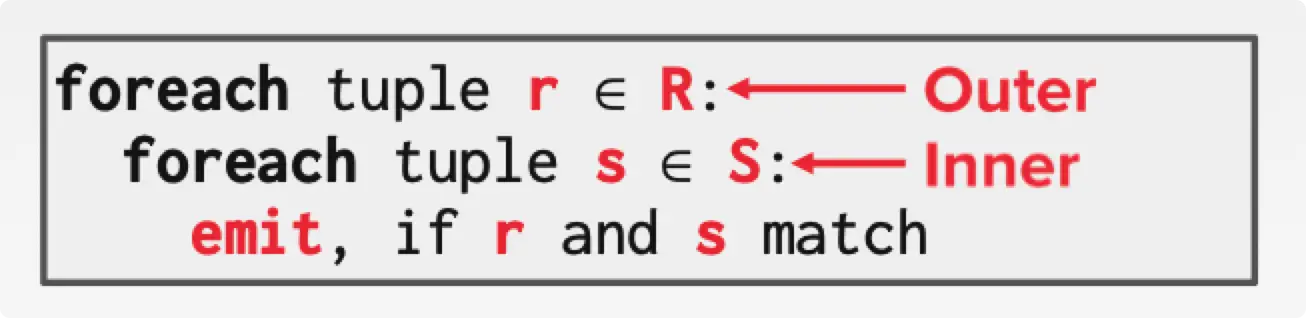
假设表 $R$ 有 $M$ 个 page,$m$ 个 tuple。表 $S$ 有 $N$ 个 page, $n$ 个 tuple。
$$
Cost=M+(m\cdot N)
$$
这种算法性能低下,inner 里面的数据会被重复扫描,浪费时间。如果 inner 表的数据能够一次性全部存放到内存里面,则可以使用该算法,这样 outer 和 inner 都均只需要读取一次。
$$
Cost=M+N
$$
Block Nested Loop Join
可以使用基于 block 的 Nested Loop Join 来减少遍历的次数。每一个匹配一个 block 的 outer table,这种做法可以减少磁盘的寻道时间。
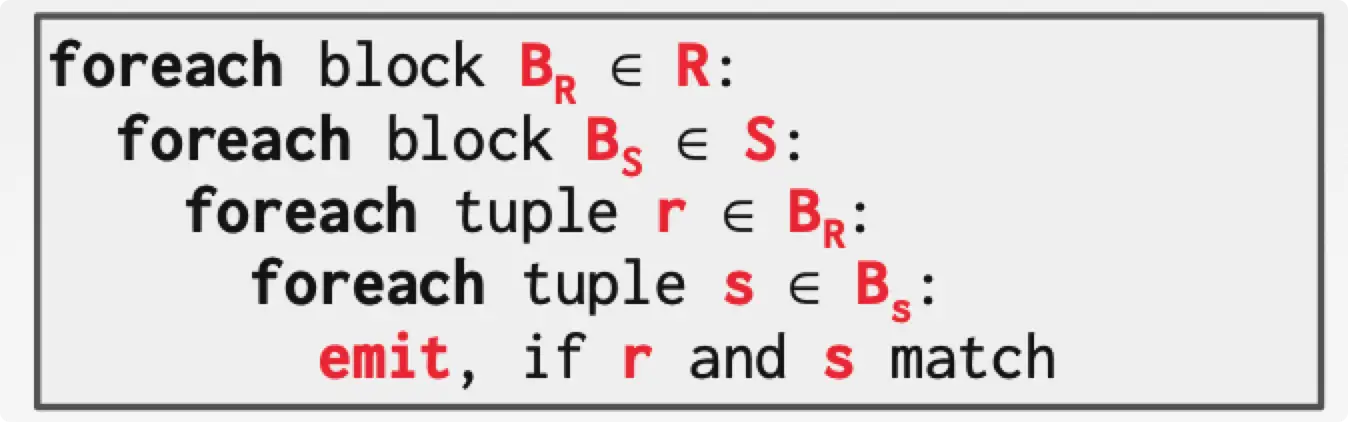
假设有 $B$ 个 buffers,outer table 使用 $B-2$ 个 buffer,一个 buffer 用于 inner table,另一个 buffer 用于 output。
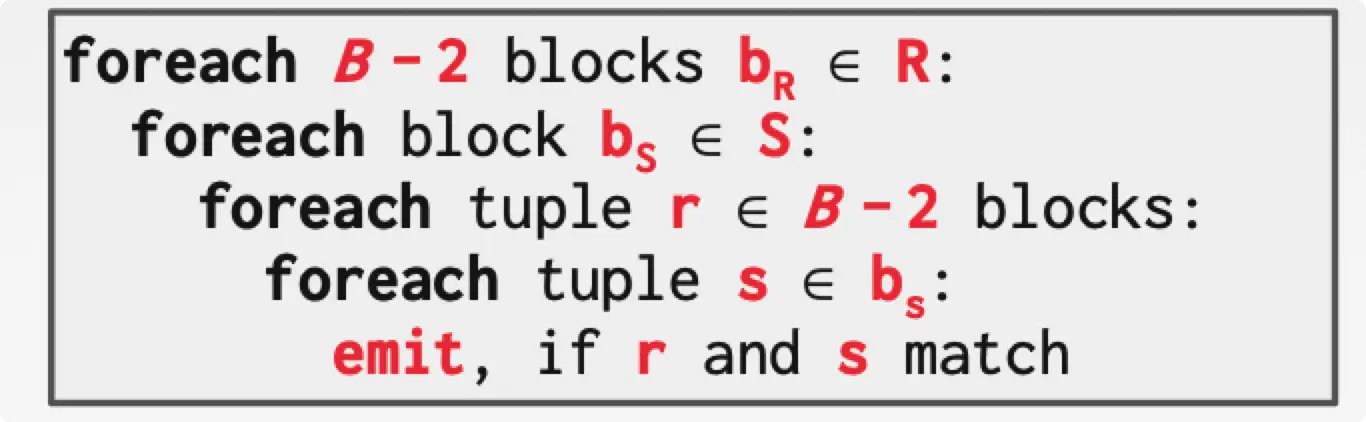
$$
Cost=M+(\lceil \frac{M}{B-2} \rceil \cdot N)
$$
Index Nested Loop Join
可以通过 index 来查找 inner table,避免每一次匹配 outer table 的一个 tuple 时需要遍历整个 inner table。
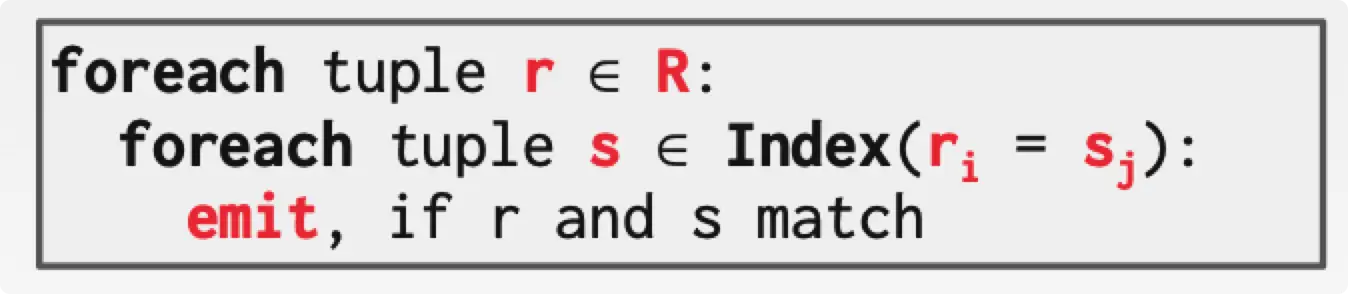
假设每一次索引的耗时是常量 $C$。
$$
Cost=M+(m\cdot C)
$$
优化
- 选择尽可能小的表作为 outer table。
- 缓存尽可能多的 outer table,针对于 block nested loop join,看 cost 可以看出来。
- 通过遍历 inner table 或 index 的方法来匹配 outer table 的每一个 tuple。
Sort-Merge Join
分两阶段:
- Sort,inner table 和 outer table 同时根据 join keys 进行排序,可以使用 external merge sort 处理。
- Merge,弄两个指针,一个 inner table,一个 outer table,同时滑动。
- 输出的结果已经是按照 join keys 排序的。
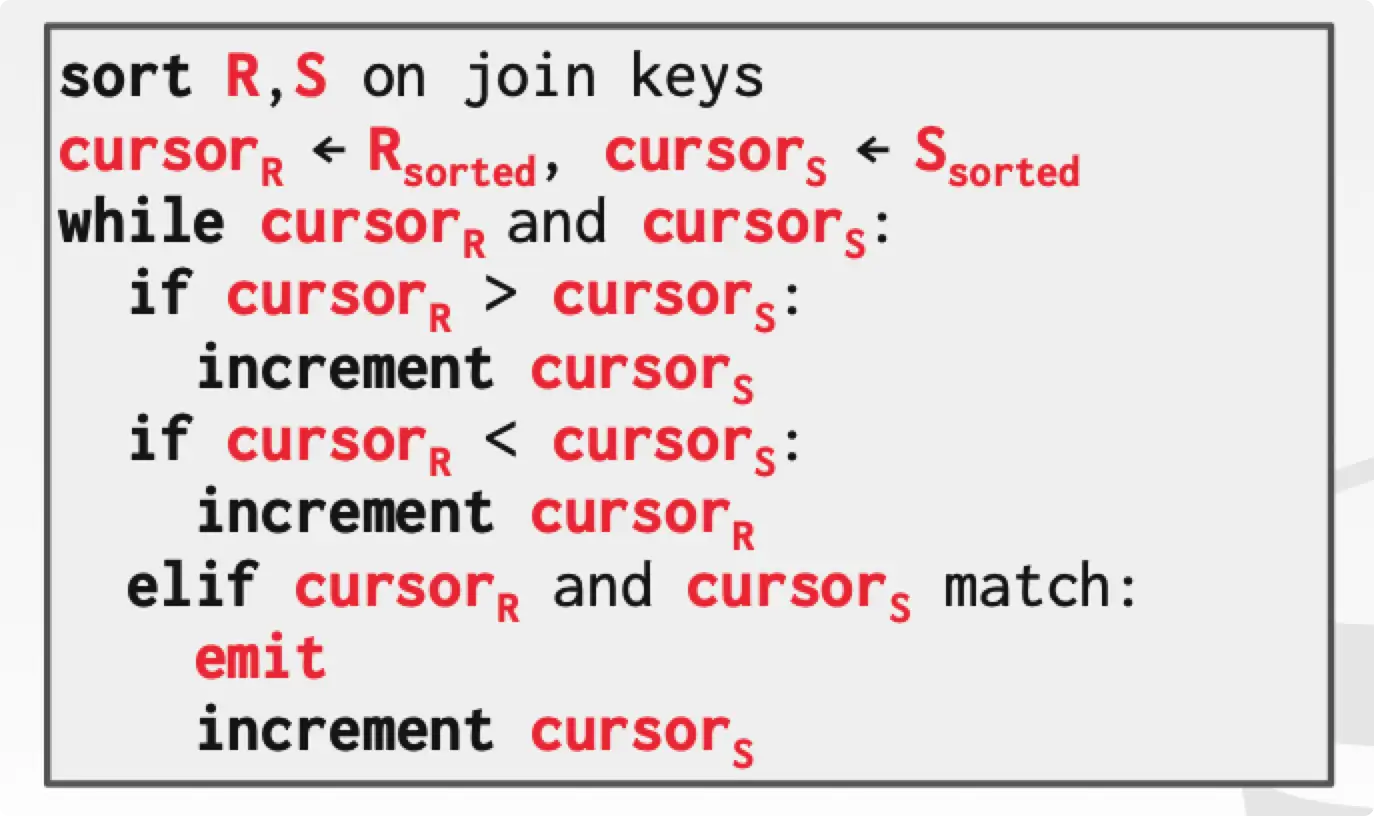
$$
Sort\ Cost(R)=2M\cdot (1+\lceil log_{B-1}\lceil\frac{M}{B}\rceil\rceil)
$$
$$
Sort\ Cost(S)=2N\cdot (1+\lceil log_{B-1}\lceil\frac{N}{B}\rceil\rceil)
$$
$$
Merge\ Cost=M+N
$$
$$
Total\ Cost=Sort+Merge
$$
Hash Join
基本都是分为 build hash table 和 probe 两阶段。
Basic Hash Join
- Build:扫描 outer table,基于 hash 函数 $h_1(s)$ 建立 hash table。
- Probe:扫描 inner table,如果 hash table 命中(同样使用 $h_1(s)$ 函数),则输出。
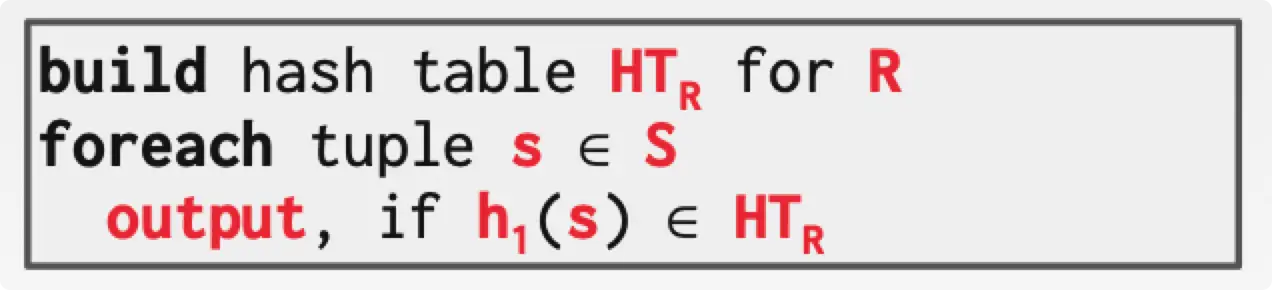
Build 阶段可以同时建立一个 BloomFilter 来帮助查询。BloomFilter 通常很小,可以直接缓存在缓存里面。
Grace Hash Join
Basic Hash Join 存在建立 hash table 时 buffer 不足的问题。虽然可以通过换页的方式处理,但是这样的换页是随机的,可能换出的 page 马上被换回来,效率不高。
Grace Hash Join 在 build 阶段,同时建立 outer table 和 inner table 的 hash table,然后将 hash table 划分为多个 partition,每次只比较相同序号的 partition,partition 的比较采用 nested loop join 的方式生成结果。因为相同 join key 的 tuple 必然出现在同一个 partition 里面,所以当两个 partition 比较完后,可以换出 partition,反正不会再需要了。
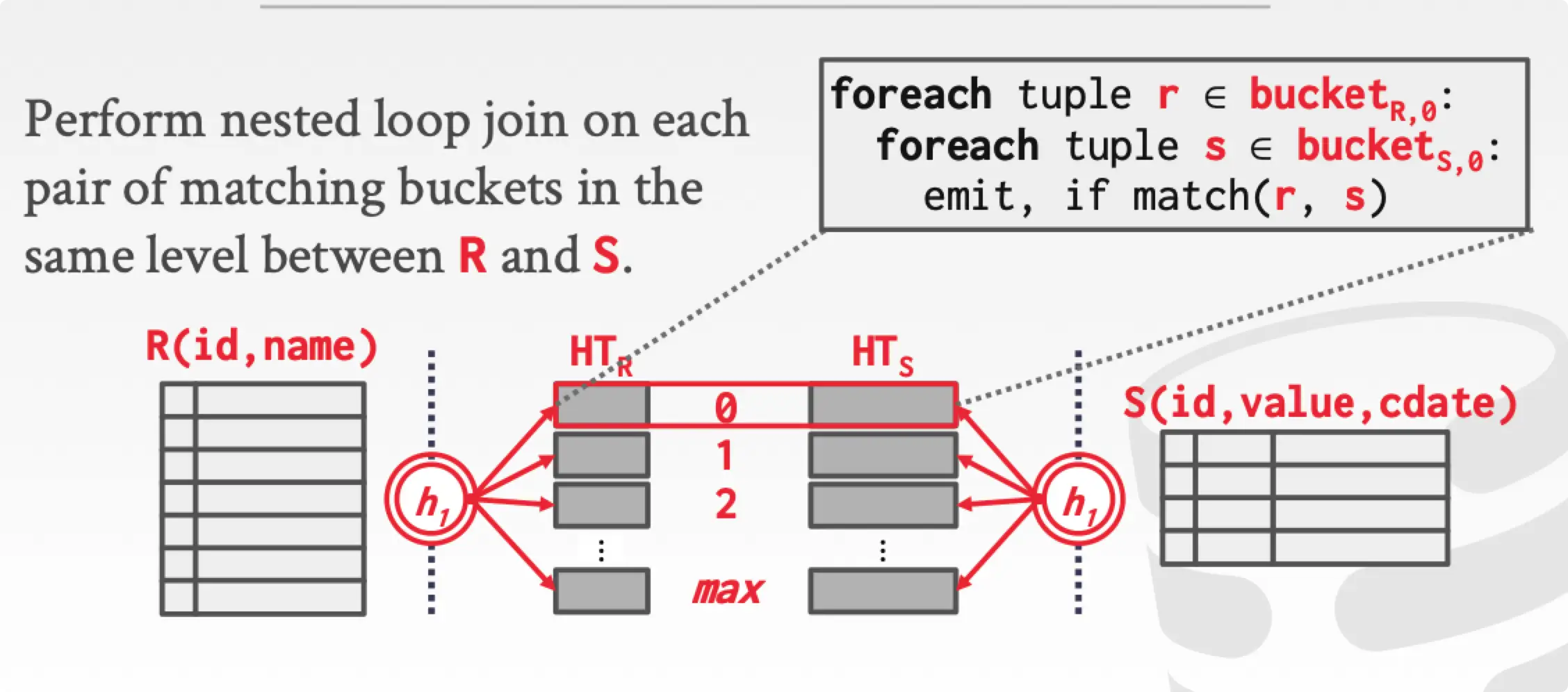
$$
Partition\ Phase\ Cost=2(M+N)
$$
$$
Probing\ Phase=M+N
$$
$$
Total\ Cost=3(M+N)
$$
Join 小结
IO Cost 为一个近似值。
Example 为一个预估时间。
| Algorithm | IO Cost | Example |
|---|---|---|
| Simple Nested Loop Join | $M+(m\cdot N)$ | 1.3 hours |
| Blocked Nested Loop Join | $M+(M\cdot N)$ | 50 seconds |
| Indes Nested Loop Join | $M+(M\cdot C)$ | Variable |
| Sort-Merge Join | $M+N+(sort\ cost)$ | 0.75 seconds |
| Hash Join | $3(M+N)$ | 0.45 seconds |
通常 Join 算法都是采用 Hash Join,但是如果数据已经被实现排序过,可以使用 Sort-Merge Join。
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/database-query-processing
 微信扫一扫
微信扫一扫