在单机上实现原子提交没啥好说了,可以通过 logging 来保证,但是在分布式系统中,情况就不简单。很多人会把 2PC/3PC 这类算法叫做分布式一致性算法,但是我个人觉得它们叫原子提交协议更合适(atomic commitment protocol ),因为它们只是把多个操作融合为一个原子操作,要么全部成功,要么全部失败。具体可以看 https://exactly-once.github.io/posts/notes-on-2pc/ 这篇文章。
Two-Phase Commit(2PC)
具体的算法流程我这里不会讲了,网上资料很多,可以自己参考。
先从网上扒一张 2PC 的图:
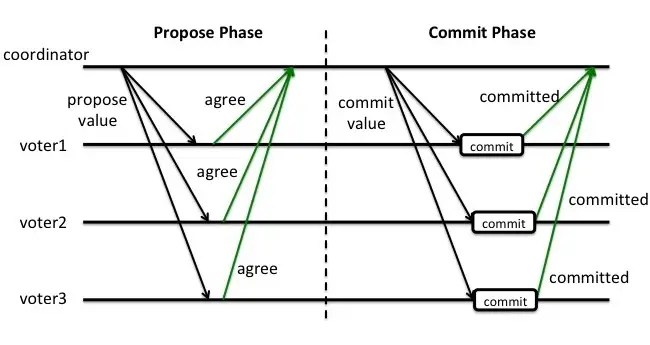

2PC 有一个很明显的问题就是它是一种 blocking 算法。比如当 coordinate 在发送完 propose 之后挂了,所有参与者都将阻塞在那里,等待着 coordinate 发送 commit 或 abort 指令。此时又因为这些参与者已经开启了事务(但是又没有结束),它无法再响应别的请求,也就是阻塞了。这一点很多文章会说道,这里不细说了。
错误处理机制
只有 Coordinate 挂了
启动一个替代 Coordinate,然后轮询所有参与者,然后继续推进即可。例如有一个参与者已经 commit 了,则说明可以 commit,那么向所有参与者发送 commit 继续推进。
只有参与者挂了,且不可恢复
那就不用管它了,反正它不可恢复,永远上不了线。
只有参与者挂了,可恢复
恢复后咨询 Coordinate 获取状态,恢复自己。为什么可以这么做?因为 Coordinate 保存着决议的最终状态,就是 commit 或 abort 状态,参与者可以通过和 Coordinate 通讯来恢复自己。
Coordinate 和参与者在第一阶段挂了
由于这时还没有执行 commit 操作,新选出来的 Coordinator 可以询问各个参与者的情况,再决定是进行 commit 还是 roolback。因为还没有 commit,所以不会导致数据一致性问题。
Coordinate 和参与者在第二阶段挂了,但是挂的参与者还没有执行 commit/rollback 操作
这种情况下,当新的 Coordinator 被选出来之后,他同样是询问所有参与者的情况。只要有机器执行了 abort(roolback)操作或者第一阶段返回的信息是 No 的话,那就直接执行 rollback 操作。如果没有人执行 abort 操作,但是有机器执行了 commit 操作,那么就直接执行 commit 操作。这样,当挂掉的参与者恢复之后,只要按照 Coordinator 的指示进行事务的 commit 还是 roolback 操作就可以了。因为挂掉的机器并没有做 commit 或者 roolback 操作,而没有挂掉的机器们和新的 Coordinator 又执行了同样的操作,那么这种情况不会导致数据不一致现象。
Coordinate 和参与者在第二阶段挂了,但是挂的参与者已经执行了 commit/rollback 操作
这里我具体说一下,假设原来 Coordinate 打算执行 rollback 操作,然后 Coordinate 将 rollback 操作发送给 A 节点后挂了,巧的是 A 节点在执行完 rollback 节点后也挂了。这时新的 Coordinate 上线,它查询活着的参与者,发现大家都是在等待 commit/abort 的指令,那么新 Coordinate 应该执行 commit 还是 abort 指令呢。如果执行了 commit,然后之前挂了的那个参与者(它执行的是 rollback)上线了,就会产生数据的不一致性。所在在这种情况下,是无论如何都不可恢复的。
小结
总结下,2PC 实现固然简单,但是会产生阻塞和数据不一致的问题。然而 3PC 就能解决了吗,其实 3PC 也就只有解决了阻塞问题,并没有能力解决不一致问题。所以业界普遍还是采用 2PC 的设计,毕竟 3PC 这么复杂也没能解决啥问题。
Three-Phase Commit(3PC)
3PC 主要是用于解决 2PC 中的阻塞问题,而不是一致性问题。
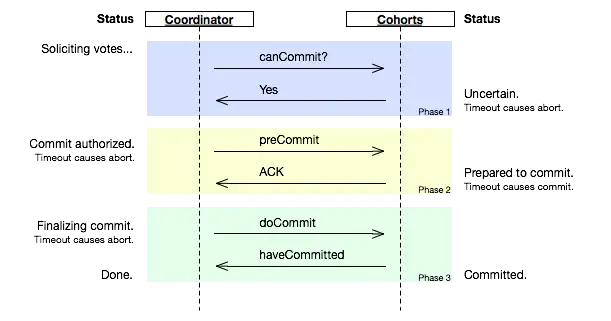
网上扒的图,里面 Cohorts 就是参与者。
可以看到 3PC 在 phase1 和 phase2 加入了定时器。Phase1 阶段如果没有收到 Coordinate 的消息,则自动执行 abort 操作。Phase2 阶段如果没有收到 Coordinate 的消息,则自动执行 commit 操作。有效解决了 2PC 中因为 Coordinate 失联导致的阻塞问题。
错误处理
3PC 的错误处理机制其实和 2PC 中的类似,新上任的 Coordinate 可以通过查询参与者的状态,做出相关决定,以此继续推进。
我这里举个例子,比如在 Phase2 阶段,Coordinate 决定 abort 操作。当 Coordinate 发送 abort 给一个节点后挂了,新 Coordinate 通过查询所有参与者状态,发现有一个参与者已经 abort 了,那说明之前 Coordinate 之前做的决定是 abort,此时 Coordinate 发送 abort 给其它参与者。
但是 3PC 同样没有解决一致性问题,同样考虑在 Phase2 阶段,假设 A 节点收到了 Coordinate 的 preCommit 消息,然后 Coordinate 挂了。然后网络产生了分区,A 节点和 B/C/D 失联。注意此时 B/C/D 还没有收到 preCommit 消息,按照超时规则,A 节点超时自动 commit,而 B/C/D 超时自动执行 rollback 操作。此时不一致的情况产生。
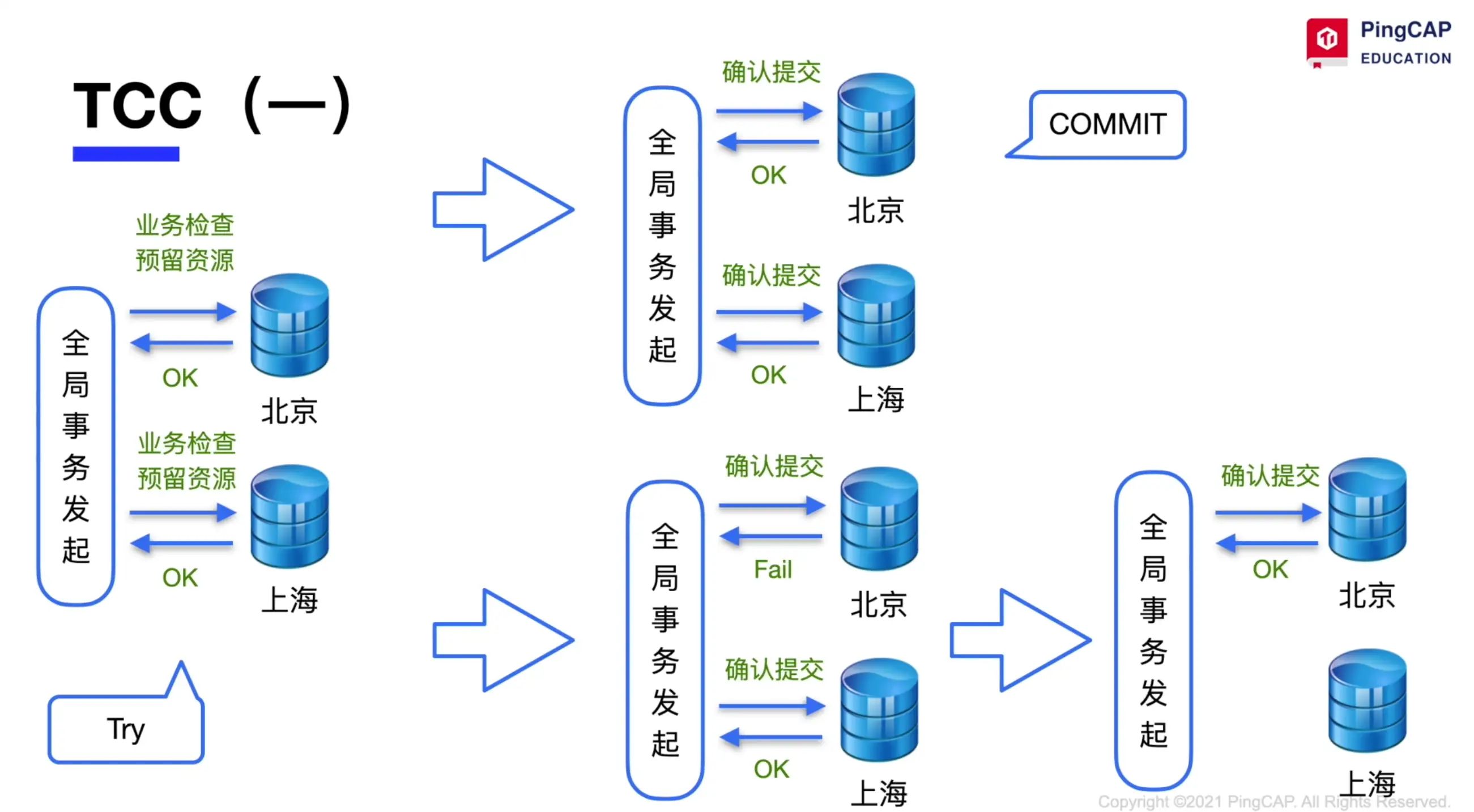
TCC Try-Confirm/Commit-Cancel
分两个阶段:
Try:
Coordinator 向参与者发送 try 请求,在各个参与者上面开启事务,锁住相关资源。
Confirm/Cancel:
如果 try 成功,Coordinator 执行 commit 操作,发送 commit 到各个参与者上。当有部分节点 commit 失败,Coordinator 会不断重试,直到 commit 成功为止。
如果 try 失败,Coordinator 执行 rollback 操作,发送 rollback 到各个参与者上。同上,Coordinator 会不断重试,直到全部参与者 rollback 成功为止。
Example:
SAGA
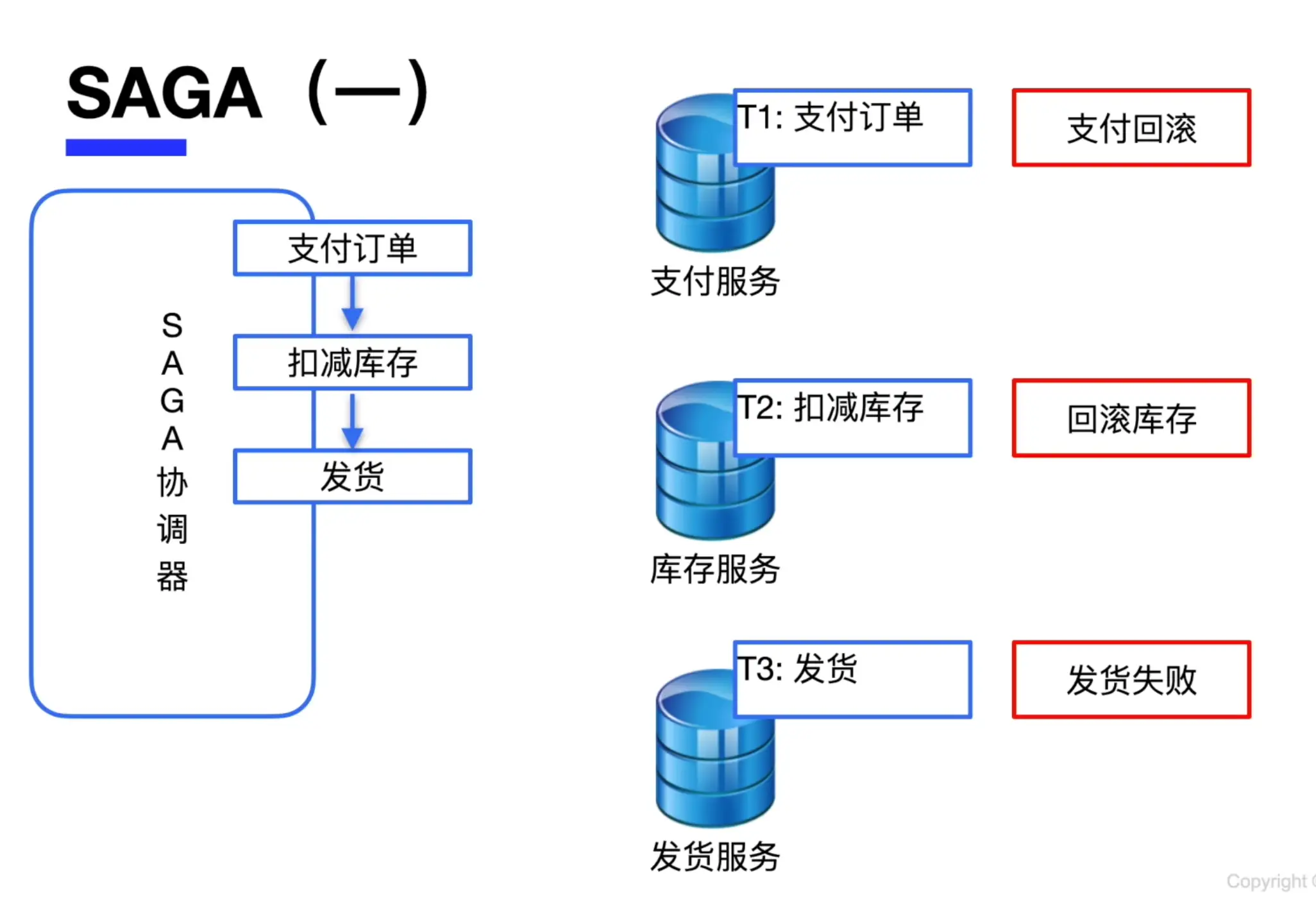
SAGA 通过将一个大事务拆分为多个子事务,逐个处理。如上图,原本支付订单,扣减库存,发货为一整个事务,SAGA 将其划分为三个部分,其中每一步事务都有其独立的回滚方案。
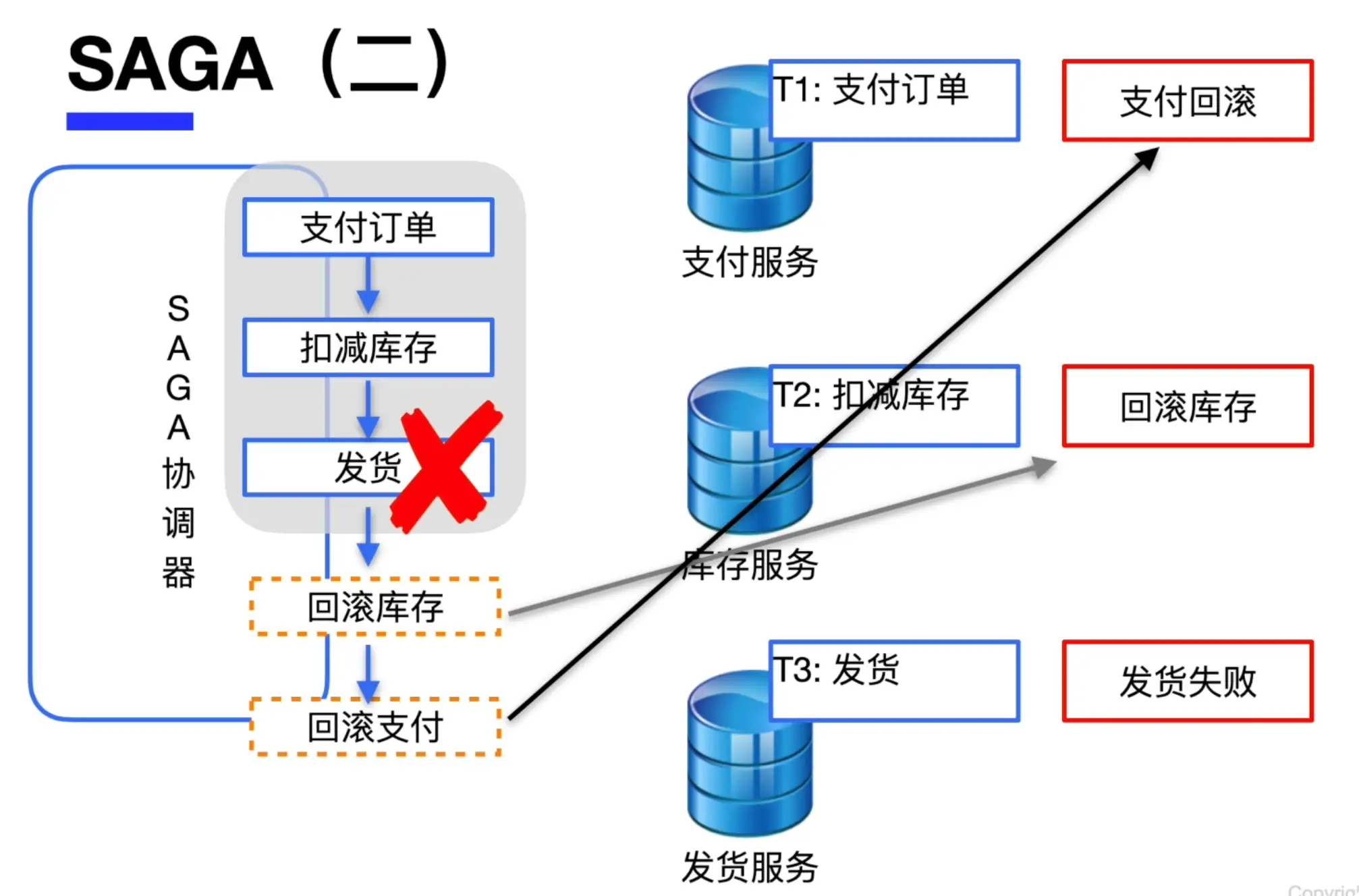
如上图,当发货的事务 commit 失败,需要执行回滚,它就会执行对应的回滚操作,将已执行的操作按顺序逐个回滚(先回滚库存,再回滚支付)。
这种架构适合微服务架构,比如这个例子中支付,库存和发货各为一个独立的微服务,有其独立数据库,用这种办法可以很好的解决事务的原子提交问题。
参考资料
https://exactly-once.github.io/posts/notes-on-2pc/
https://matt33.com/2018/07/08/distribute-system-consistency-protocol/
https://learn.pingcap.com/learner/course/390002
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/distributed-atomic-commit-protocols
 微信扫一扫
微信扫一扫
评论列表(1条)
关于2PC中的“Coordinate 和参与者在第二阶段挂了,但是挂的参与者已经执行了 commit/rollback 操作”这种情况,原文说的这个会引起数据不一致,但我觉得应该不会。Coordinate既然已经推进到第二阶段了,那么其必然在第一阶段已经有决策了(commit或者abort),此时正常的2PC算法为了保证durability,都会将Coordinate的状态记录下来,那么即使其在第二阶段crash了,等Coordinate恢复过来读取自身持久化存储中记录的状态就能知道自己应该做何决策。比如自己应该commit,那么自己之前就不会对任何participant发出DoAbort的命令,也就不存在coordinator做出了commit的决策,但是有的挂掉的participant却执行了abort的这种数据不一致的情况。