本篇文章主要介绍如何搭建完全分布式的 Hadoop 集群,介于 Hadoop 配置复杂,特此写下此篇文章记录。
基础准备
这一次我使用三台服务器组建一个 Hadoop 集群,三台机器我通过虚拟机(Parallel Desktop)模拟,当然大家也可以使用 VirtualBox 或 VMWare 等软件。
三台机器配置信息如下:
CPU:双核
内存:2G
磁盘:12G
root 密码:123456
系统:Centos 8.0 (Minimal Install)

环境安装
更新系统软件(可选)
其实不更新也没啥事估计。
允许 dnf update -y 。
从 Centos 8 开始内置了 dnf 命令,所以这里我使用 dnf 命令代替了 yum 。
安装 openjdk 1.8
执行 dnf install java-1.8.0-openjdk-devel.x86_64 -y
安装 vim
为了方便后面 Hadoop 配置文件的编辑,我们安装一个 vim 。
执行 dnf install vim -y
安装 tar
安装解压软件,用于解压 tar 的压缩文件。
执行 dnf install tar.x86_64 -y
机器克隆
通过虚拟机管理软件将这台机器克隆 2 台当做 slave 节点。
通信配置
我们要让三台机子组成一个小型局域网。
我这里三台机子分配的虚拟 IP 为:
- Master : 10.211.55.11
- Slave1 : 10.211.55.12
- Slave2 : 10.211.55.13
hostname 编辑(非必须,只是为了命令行方便管理,不然都是千篇一律的 localhost )
我这里以 master 节点为例:
执行 hostname 命令我能看到默认为 localhost.localdomain 。
执行 hostnamectl set-hostname master ,重启系统即可。
hosts 文件编辑
修改三台机子的 /etc/hosts 文件,添加如下代码:
10.211.55.11 master 10.211.55.12 slave1 10.211.55.13 slave2
静态 IP 配置(可选)
我这里主机默认的 IP 是通过 DHCP 服务获取的,如果下次分配的地址变了,会导致 3 台机子之间的通讯出现异常。所以这里我们配置 Centos 8 改为静态 IP 。
编辑 ifcfg-xxxx
xxxx 一般是你的网卡名,这里我输入命令 vim /etc/sysconfig/network-scripts/ifcfg-ens18 编辑我的网卡配置信息。
修改 BOOTPROTO="static" ,在文件后面追加 IP 地址,网关等信息:
IPADDR=10.211.55.11
NETMASK=255.255.255.0
GATEWAY=10.211.55.255保存后输入命令 systemctl restart NetworkManager 重启网络(Centos 7 命令为 systemctl restart network)。
权限配置
系统安装完默认使用 root 账号, hadoop 如果在 root 下运行不安全,需要额外配置,为了省事,这里我们在三台机子里均创建一个名为 hadoop 的用户。
以某一节点为例:
执行 adduser hadoop 即可创建 hadoop 用户,执行 passwd hadoop 为 hadoop 用户创建密码,这里密码为 123456 。(第一次系统会提示 BAD PASSWORD,密码强度不够,你再输入一次即可)。
SSH 免密登入
我们需要配置 master 主机到 slave1 , slave2 和其本身的 SSH 免密登入。
- 先执行
su hadoop切换到 hadoop 用户。 - 在 Master 主机执行
ssh-keygen -t rsa,一路回车,生成密钥。 - 分别执行
ssh-copy-id hadoop@master,ssh-copy-id hadoop@slave1和ssh-copy-id hadoop@slave2将密钥拷贝到三个节点。完成后我们可以输入ssh hadoop@slave1进行测试。
注意本机 master 也需要免密设置,因为我们后面会将 master 既做管理节点,也做一个 slave 节点。
Hadoop 分布式架构介绍
- master 节点为母节点,负责调度两个 slave 节点,同时其自己也充当一个 slave 节点。
- NameNode 运行在 master 节点上,负责 DataNode 的统一管理。
- SecondaryNode 运行在 master 节点上,辅助 NameNode 的运行。
- ResourceManager 运行在 master 节点上,负责 yarn 任务的调度。
- slave 为奴隶节点(一般叫 worker),负责运算、存储。
- DataNode 运行在 slave 上,一个数据节点,存储数据。
- NodeManager 运行在 slave 上,负责执行任务。
Hadoop 下载安装
三台机子均下载 hadoop文件到 /home/hadoop 目录下,进行解压(注意权限问题,权限都要属于 hadoop 用户,防止后面出现意想不到的问题)
命令行示例:
su hadoop
cd /home/hadoop
wget http://apache.mirror.colo-serv.net/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
tar -zxvf hadoop-3.2.1.tar.gzJAVA_HOME 配置
在 Centos 8 中 OpenJDK 8 的默认安装路径在 /usr/lib/jvm/java-1.8.0-openjdk 下,我们打开 ~/hadoop-3.2.1/etc/hadoop/hadoop-env.sh 修改一行的代码为
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk推荐再补充一行配置,可以防止 pid 文件默认存放在 /tmp 被系统自动删除导致的集群不能正常关闭的问题。
export HADOOP_PID_DIR=/home/hadoop/data/tmp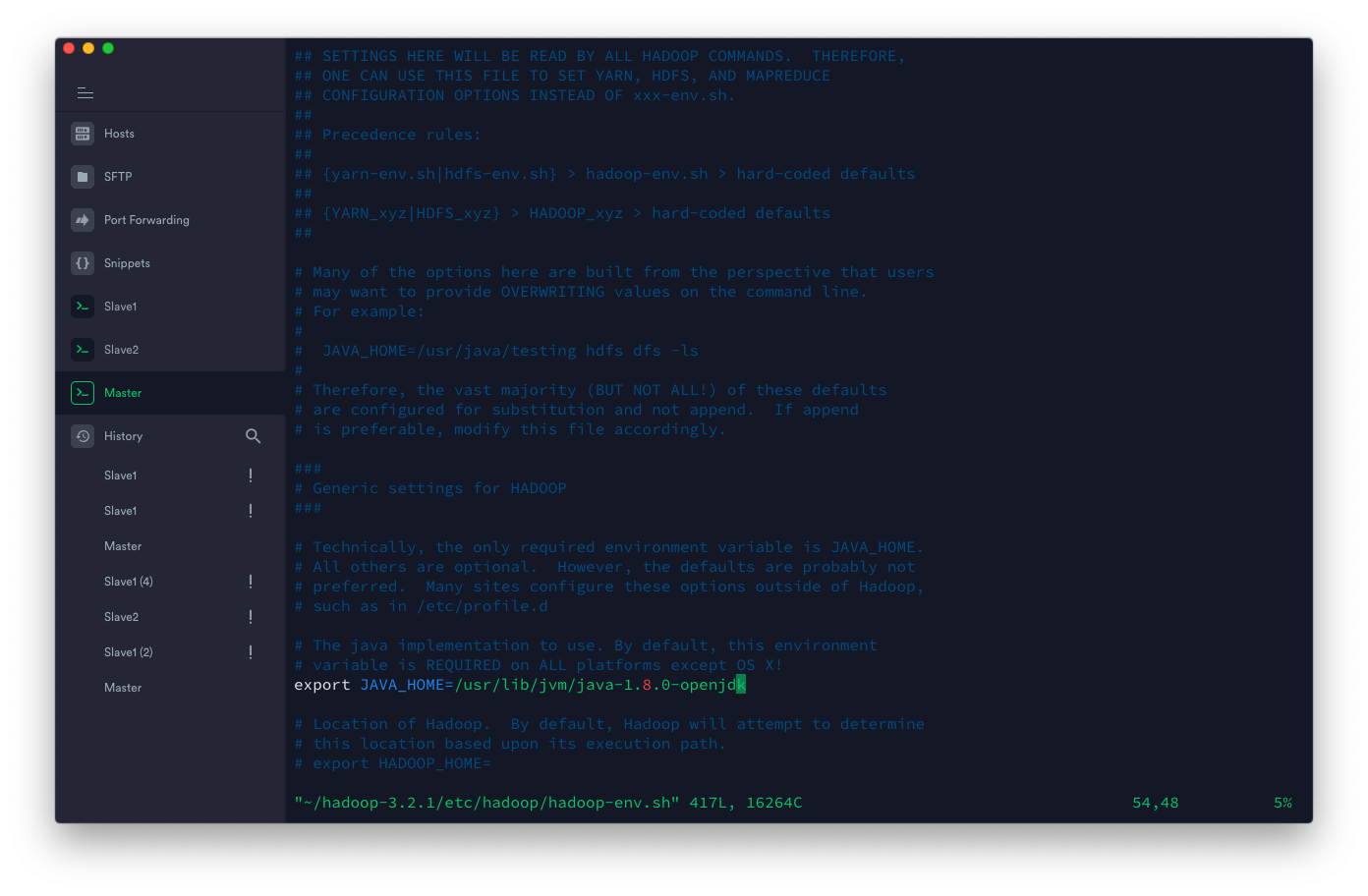
NameNode 配置
编辑 ~/hadoop-3.2.1/etc/hadoop/core-site.xml 的代码如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>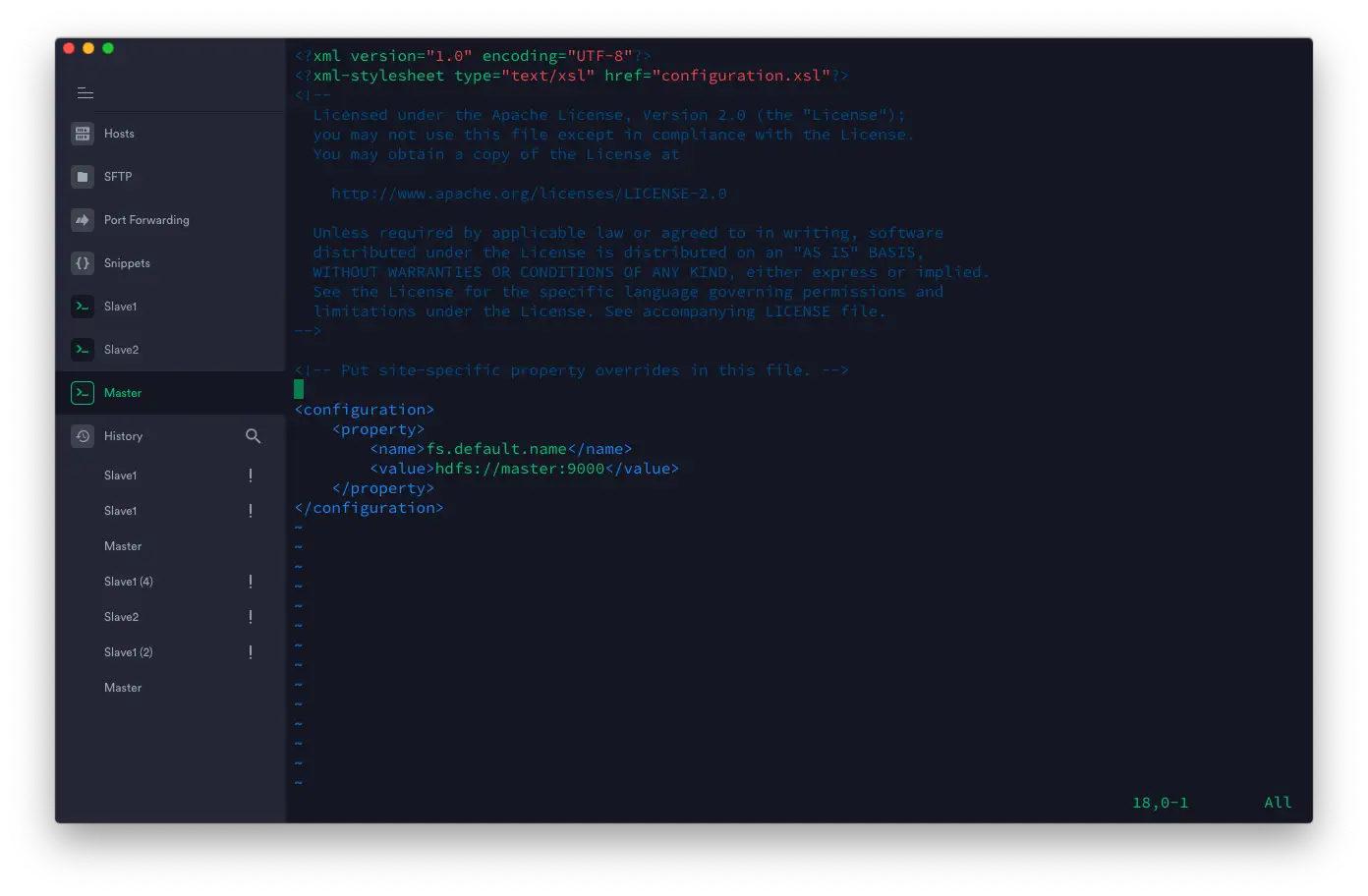
HDFS 配置
编辑 ~/hadoop-3.2.1/etc/hadoop/hdfs-site.xml 代码如下:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>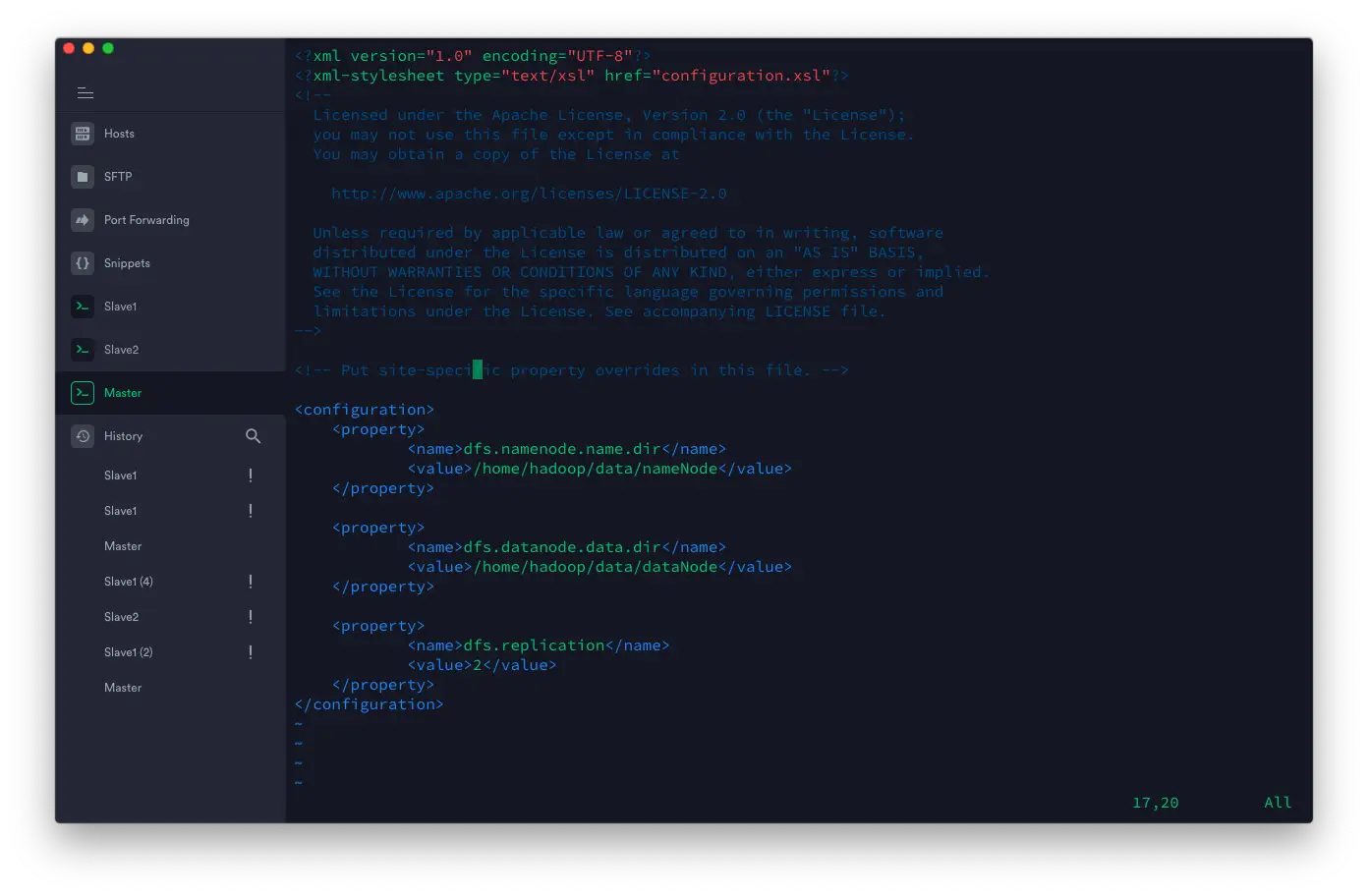
其中最后一项设置 dfs.replication 表示在 Hadoop 集群中一份文件要存在几份备份,数字的设置不要大于真实存在机器的数量。
例如我有三个计算节点(slave),
dfs.replication的值不能大于 3。
设置 YARN
编辑 ~/hadoop-3.2.1/etc/hadoop/mapred-site.xml 代码如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>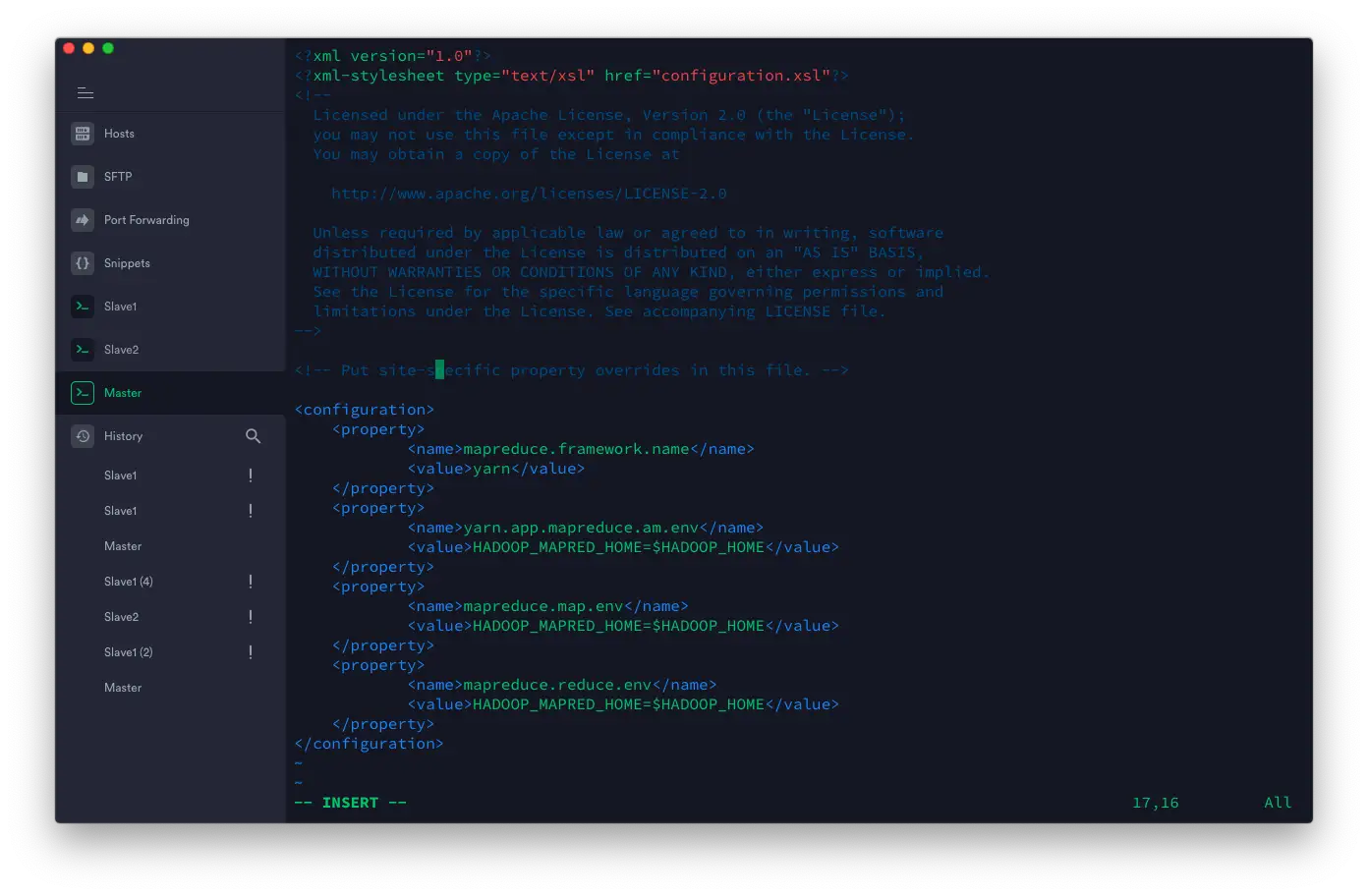
编辑 ~/hadoop-3.2.1/etc/hadoop/yarn-site.xml 代码如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>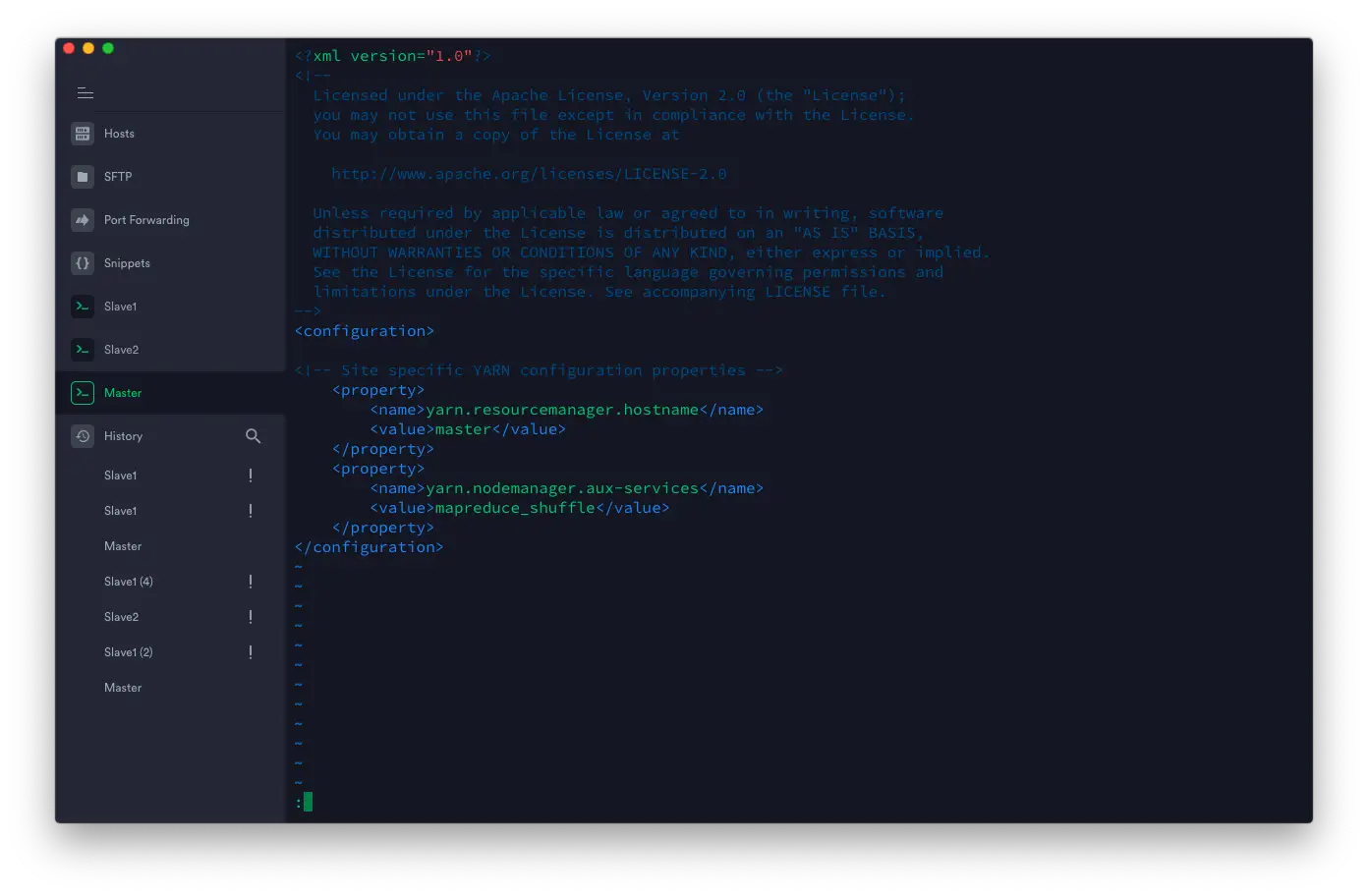
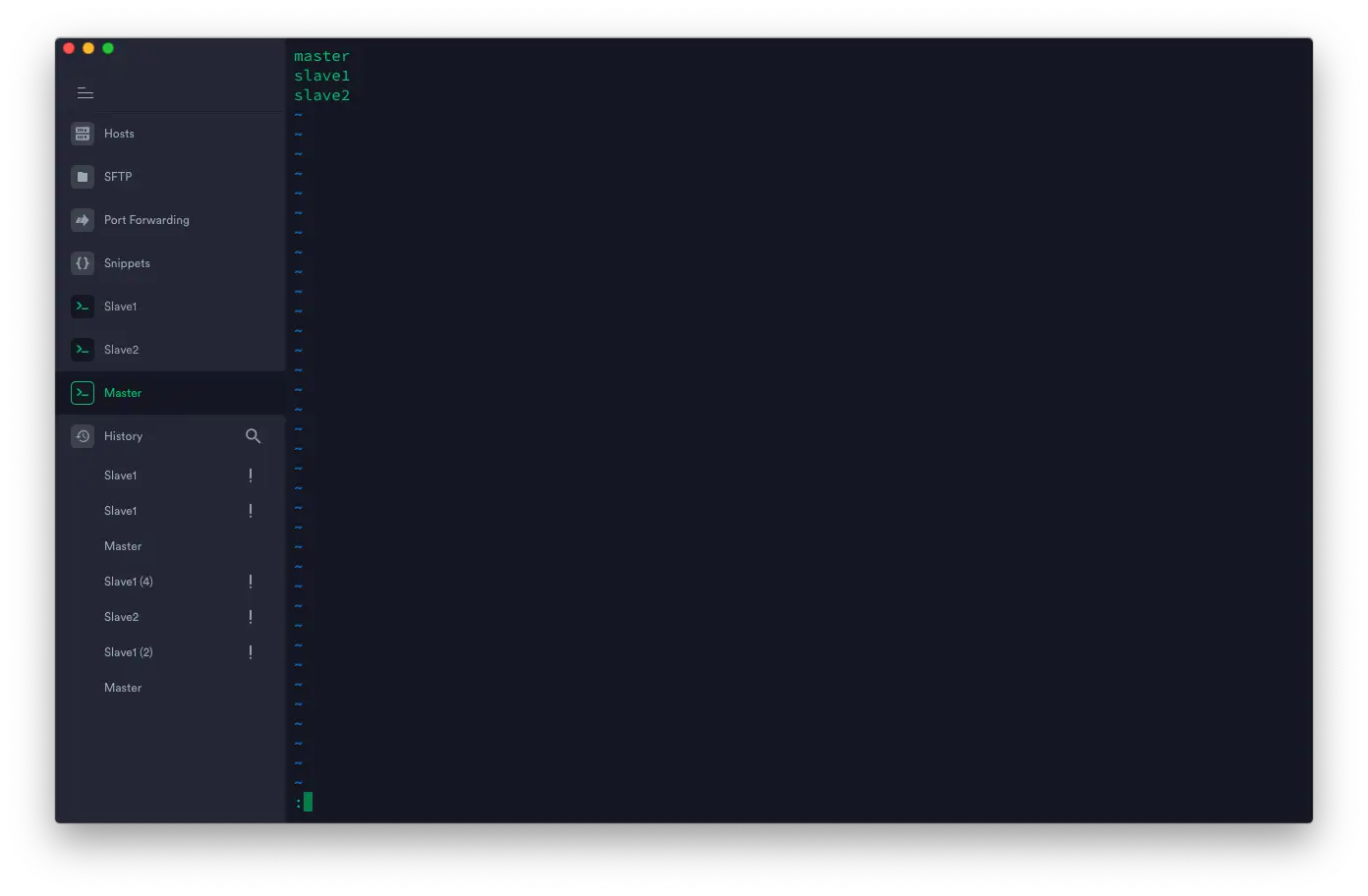
配置 Workers 节点
slave 这里的叫法为 worker ,编辑 ~/hadoop-3.2.1/etc/hadoop/workers 代码如下:
master slave1 slave2
我这里填写了 master 节点,意味着 master 节点不光充当管理,自己也承担了一个 worker 节点。
拷贝配置到各个 slave 节点
执行命令:
scp hadoop-3.2.1/etc/hadoop/* slave1:/home/hadoop/hadoop-3.2.1/etc/hadoop/ scp hadoop-3.2.1/etc/hadoop/* slave2:/home/hadoop/hadoop-3.2.1/etc/hadoop/
将配置文件拷贝到另外两个 slave 节点。
运行测试
关闭防火墙
首先要关闭三个节点的防火墙,同时禁止开机运行,防止在内网通信时出现意想不到的问题,执行如下命令:
systemctl stop firewalld
systemctl disable firewalldHDFS 开启
我们在 master 节点执行下面命令,对 HDFS 进行初始化,./hadoop-3.2.1/bin/hdfs namenode -format 。
随后执行 ./hadoop-3.2.1/sbin/start-dfs.sh 开启 hdfs 集群。
大家可以在 master 节点输入 jps 命令看到已经在运行的进程
4930 SecondaryNameNode
4579 NameNode
4739 DataNode
5050 Jps在 slave 节点 jps 命令可以看到:
2834 DataNode
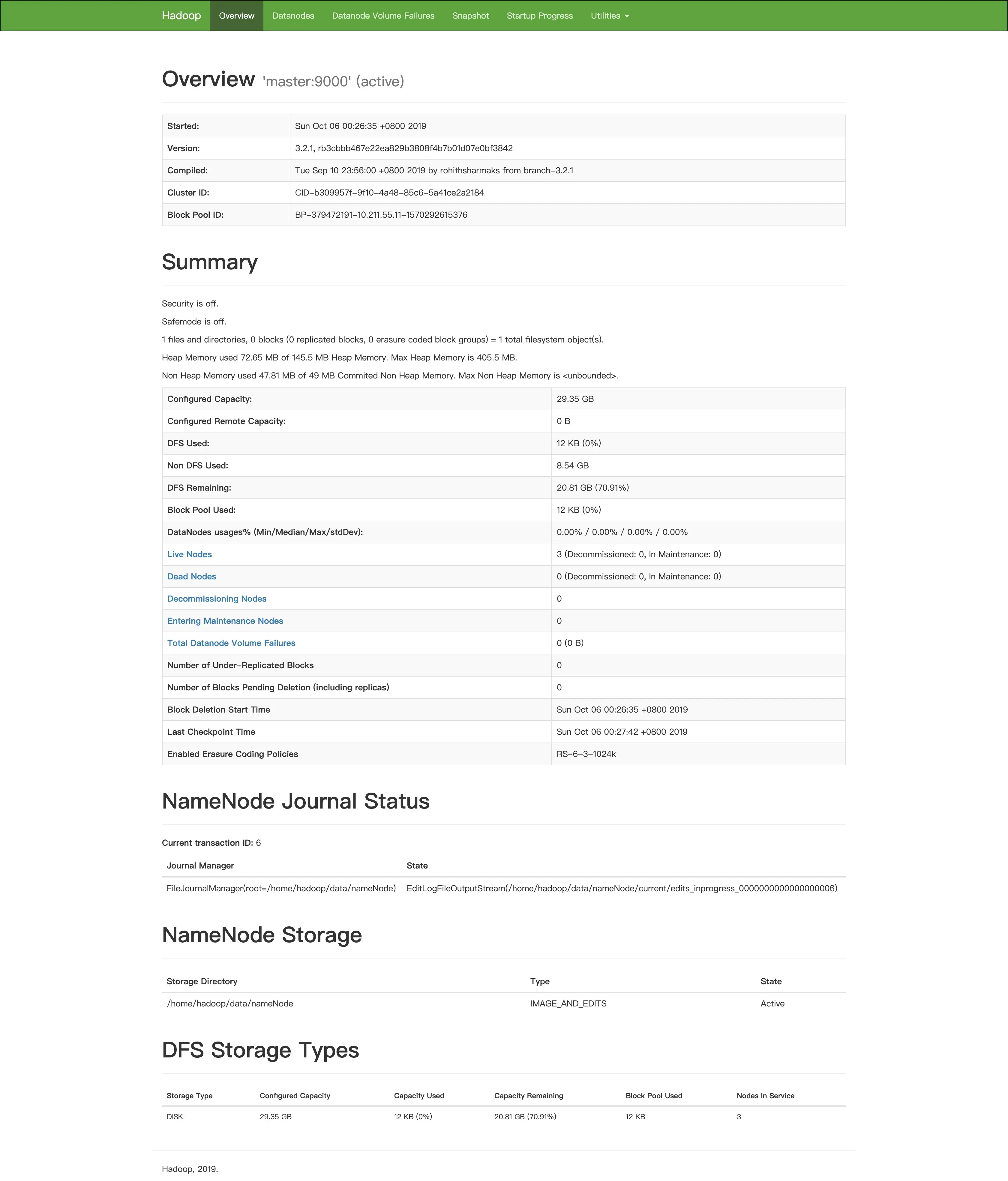
2895 Jps在浏览器访问 localhost:9870 可以看到 web 的控制界面(虚拟机的访问需要开启端口转发):
Yarn 开启
执行 ./hadoop-3.2.1/sbin/start-yarn.sh 命令即可开启,访问地址 localhost:8088 可以看到如下界面:
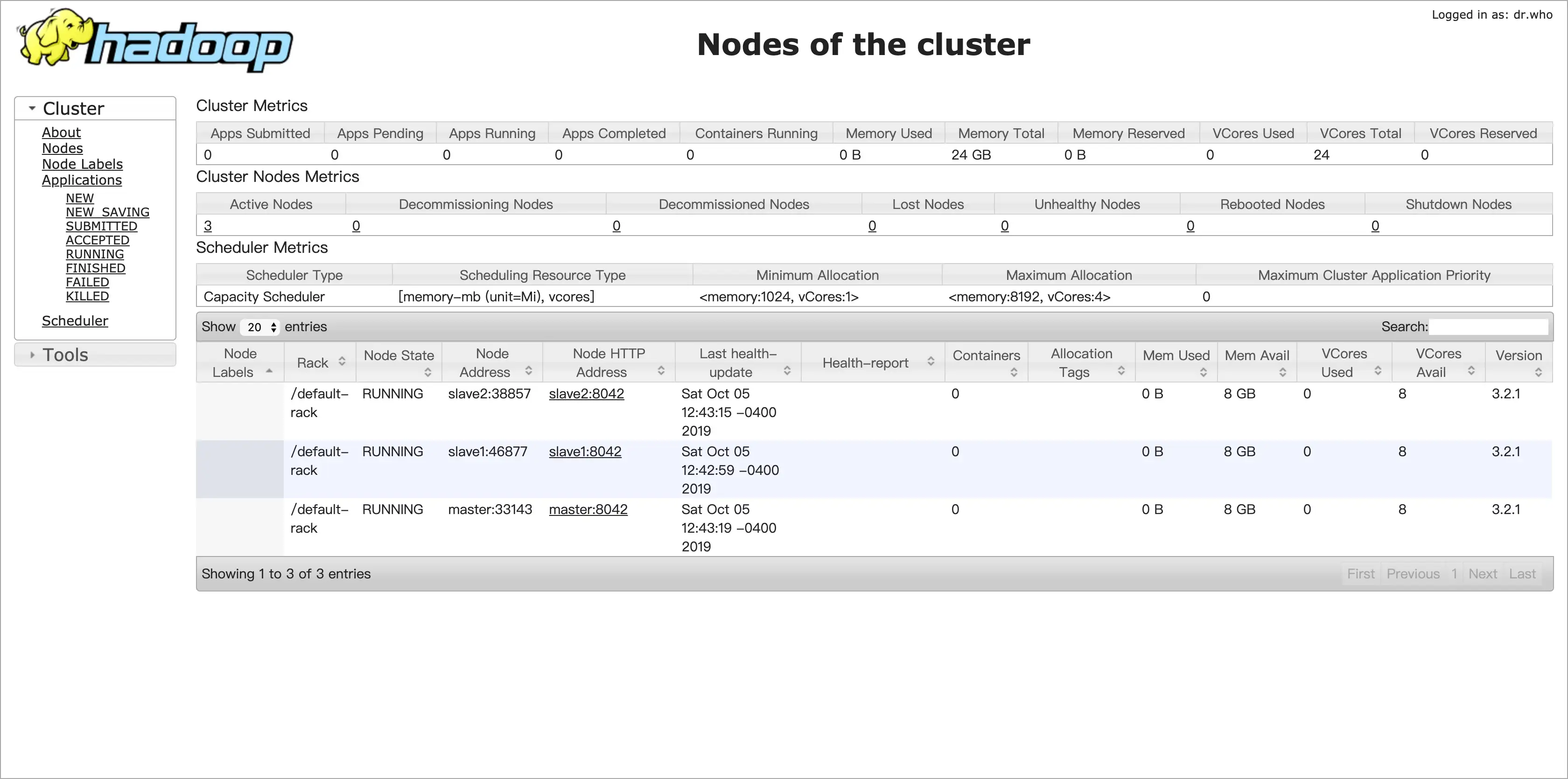
上面我们可以看到 3 个节点在正常运行。
总结
至此,完成了 Hadoop 分布式的配置,为了尽可能精简配置,很多参数都是使用默认的。其中在 hadoop 目录下的 sbin 文件夹中提供了很多有用的脚本,例如 start-all.sh 能够一键开启 hdfs 和 yarn 。大家注意关闭系统时需要使用 stop-xx.sh 脚本关闭系统。
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/install-hadoop-in-fully-distributed-mode
 微信扫一扫
微信扫一扫 