满打满算花了 25 天完成了 2021 MIT 6.824 的 4 个 lab,这里记录下自己遇到的坑和设计思路,为后续者参考。
这里个人给的难度评级是 Lab 2 > Lab 4 >> Lab 3 = Lab 1。
这里我就简单的记录下自己的设计思路和遇到的坑。
如果大家想要参考更加具体的代码实现,可以看看 https://github.com/OneSizeFitsQuorum/MIT6.824-2021。
Lab 1 MapReduce
Lab 1 要求我们实现一个 MapReduce,小试牛刀,熟悉 go 的语法。MapReduce 中间 shuffle 的临时文件存在本地磁盘即可,不需要像论文那样存在分布式文件系统中。
这里我设计成 worker 启动后就不断向 coordinator 发送 heartbeat 来索要 task。Coordinator 自己内部维护着当前 job 的 phase(MapPhase,ReducePhase)和当前 phase 的 task pool。每当一个 worker 来索要 task 时,则从 task pool 中取出一个 task 给该 worker,同时, Coordinator 启动一个异步线程检查这个 task 是否完成。如果超过 10s 还没有完成,则把这个 task 重新放回 task pool,这样也能合理的解决 straggler worker 和 worker crashed 的问题。
当 worker 通过 heartbeat 获得一个 task 时,开始执行,执行完成后发送 RPC 给 coordinator 通知已经完成,同时继续开始索要任务。如果出现没有任务的情况(就是 coordinator 中 task pool 为空),那么就 sleep 一会再继续尝试索要 task。
如果 coordinator 完成了所有任务,则在返回给 worker 中的 heartbeat 中说明已经完成任务,让 worker 自行退出。
至于生成的 shuffle 临时文件的格式,参考官方的 hints 足矣。
Lab 2 Raft
Lab 2 要实现一个 raft,很多人在做完 leader election 后就被劝退,其实没有想象的那么难。
在开始 raft 之前,做一做关于 go lock 的功课,同时在写代码的时候,一定要多多参考官方给的 guidance 和论文中的 Figure 2。尤其是 Figure 2 中的内容,没有一句话是废话,如果你少考虑 Figure 2 中的一个情况,你一定就通不过 tests。
附上两个 raft 可视化的网站,大家可以参考下。其实也就只能看看 leader election,后面的网页里面展示的都不是很详细
后台线程
我的 raft 实现中,后台维护着两个线程,一个是 ticket() 还有一个是 applier() ,ticket() 控制着超时操作,比如规定时间没有收到 heartbeat,变成 candidate 等等。applier() 负责的是监听当前的 commitIndex 和 lastApplied。applier() 使用条件变量阻塞,每当 commitIndex 有增加时,则唤醒 applier() ,让 applier() 推进 lastApplied 并提交 applyMsg。
ticket() 中的定时任务我使用的 go 的 timer 来实现,当然你用 go 自带的 ticket 来实现也可以。
Timing
Timing 非常重要,整个 raft 里面需要两个 timing,一个是发送 heartbeat 的时间间隔,是一个 stable 的时间,这里我设置的是 100 ms。另外一个是 election timeout,是一个 random 值,我的实现是 500~900 ms 里面波动(其实有点大了)。在生成 random 时间时,一定注意要重置 random seed,我一开始就没有重置 seed,然后在后面的测试中,会导致 candidate split vote 时间过长。
起初我有一点误解,以为在 follower 中的超时和 candidate 中的超时是两个 timing,实际上它们两个共用的都是 election timeout。
小技巧
死锁:不谨慎的代码很容易导致死锁,这里我用了一点小技巧来尽可能的避免死锁。如下面的代码,在 lock 中 调用 lock。这种情况是很常见的,尤其是你的代码不是一口气写的,你到后面,你可能会忘了自己 incTerm() 是会获取锁的,然后导致重复加锁。所以我会把这类方法名字定义为 xxxxWithoutLock,这样来提示自己,这个方法自己是不带锁的,但是有需要加锁才能正常执行。
func (rf *Raft) startElection() {
// xxxxx
rf.mu.Lock()
// xxxxx
rf.incTerm(term)
// xxxxx
rf.mu.Unlock()
}
func (rf *Raft) incTerm(targetTerm int) {
rf.mu.Lock()
defer rf.mu.Lock()
rf.currentTerm = targetTerm
rf.votedFor = NONE
}修改后的代码如下
func (rf *Raft) startElection() {
// xxxxx
rf.mu.Lock()
// xxxxx
rf.incTermWithoutLock(term)
// xxxxx
rf.mu.Unlock()
}
func (rf *Raft) incTermWithoutLock(targetTerm int) {
rf.currentTerm = targetTerm
rf.votedFor = NONE
}捆绑操作:还是拿上面的代码来说,根据论文,我们知道每次增加 term,就需要重置自己的 votedFor 为空,这两个操作是捆绑在一起。而你在实现 raft 的过程中,有很多地方需要增加 term,然后就可能存在一种情况,你可能某些增加 term 的地方忘记了 reset votedFor,那就很糟糕了,因为这种 bug 通常很难发现,而且出现的频率具有随机性。所以你可以用一个方法把这两步操作捆绑到一起。
捆绑操作可以用在很多地方,比如当选为 leader 后需要重置自己的 nextIndex,matchIndex 等等。
不要使用 len(rf.log)
为啥这么说,你在用 len(rf.log) 来追踪当前最新的 log index 的方法在 2A、2B、2C 都是可行的,但是当你需要实现 snapshot 时,你就会叫爸爸了,你需要把前面的这种写法全部推倒重来,然后 bug 满天飞,与其如此,还不如一开始就自己定义一个变量 logIndex int 来追踪当前最新的 log index。rf.log[0] 则存放 lastLogIndex,lastLogTerm 等信息(这个见 snapshot ),在 2D 之前为空即可。
检查 outdated reply
每一次写 RPC 返回的处理代码时,一定要再三思考,这个返回值如果是过期的怎么办。比如你已经是 leader 了,然后收到珊珊来迟的同意你成为 leader 的 reply,此时你应该直接忽略,不做任何操作。
循环线程注意实时检查 killed()
也许我们会使用到
for {
// xxxxxx
}这种循环结构,请一定检查如果 raft killed,这个 for 能不能退出。最开始我有一个地方忘记结束,导致在测试时 CPU 占用率很高,最后会导致超时。
论文 Figure 8 讲解
论文中的 Figure 8 困扰了很多人,这里解释下,Figure 8 的核心思想,就是通过 time sequence 证明一个 leader commit log 时,只能提交自己当前 term 的 log(不能提交以前 term 的 log),不然就会引起日志冲突。
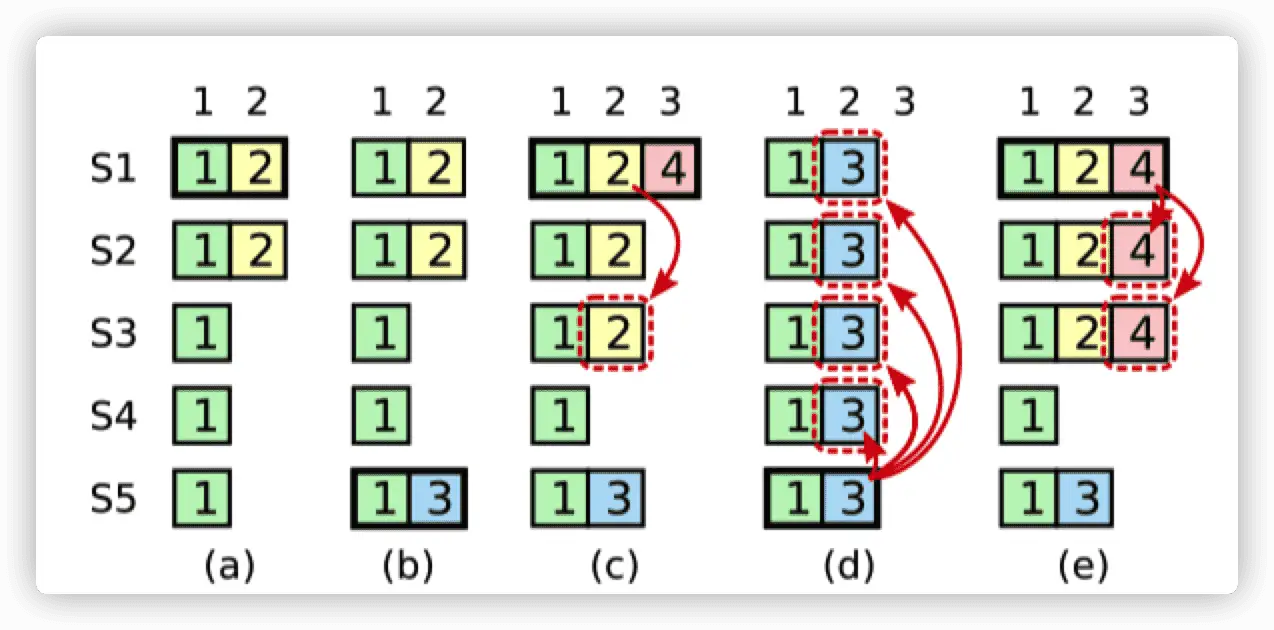

图顶上横坐标为 log index,方格里面的数字为该 log 的 term,纵坐标为 5 个节点。
- (a):S1 为 leader,复制 index=2 的数字到了 S2。
- (b):S1 崩溃,S5 上线,因为 term 递增,所以 S5 中 index=2 的 term 为 3。
- (c):S5 崩溃,S1 重新回来,然后先复制自己的 index=2 的数据到一半以上的节点。这时分为两种情况, 一我们不遵守规则,提交 index=2 的数据;二是我们遵守规则,因为 leader 只能提交当前 term 的数据,所以即使 index=2 的数据已经复制到一半以上的节点,但是 leader 并不会提交。
- (d):此图是假设我们在 (c) 中没有遵守规则,此时 S5 重新连接,他能够赢得 S2,S3,S4 的选举,因为对于它们来说,S5 的 log 是最新的(term 最大),然后 S5 复制自己 index=2 的数据到其他节点上面,可以看到原来在 S1,S2 和 S3 中 index=2 committed 的数据被来自 S5 的数据(term=3)覆盖了,违背了数据一旦被 committed 就不能修改的原则。
- (e):此图是假设我们在 (c) 中遵守了规则,因为 index =2 的数据没有被提交,即使像 (d) 中那样被覆盖也没事,毕竟没有 commit。此时 S1 同步了 index=3 的数据到一半的节点。因为 S1 的 term 为 4,且 index=3,term=4 的数据已经同步了一半以上的节点,可以 commit,然后根据 Log Matching Property 原则,之前 index=2 的数据也会被一并提交。而此时 S5 将无法修改已经提交的数据,因为它根本赢不了选举。
2A Leader Election
开始 election 发送 RPC 时,使用 go fun(){} 异步向每个节点发送 RequestVote() ,切记不要串行发送!
一旦拿到的 votes 超过一半,立马成为 leader 并且立刻开始广播心跳(不要等 heartbeat timer 到期后再发送),让那些相同 term 的 candidate 马上变成 follower(不然人家超时重新选举,term 比你大,你自己刚到手的 leader 地位就保不住了)。
成为 leader 记得重置 matchIndex 和 nextIndex。
2B Log
此时你需要实现 log 的同步,注意你需要实现 optimized AppendEntries() 来快速的定位 conflict index(论文里面写的比较粗糙,你可以参考官方给的 guidance),否则会有一个 test 是通不过的。
这里我设计的是 leader 维护着每一个 peer 的一个 replicator,也就是说,无论何时 leader 和 peer 之间的同步只会存在一个 replicator 发送 AppendEntries()(不会有并发),这能极大的降低代码逻辑的复杂度,这样相当于每一个 replicator 是一个单线程,你不需要考虑并发下的情况。Replicator 可以使用条件变量控制,当 Start() 触发或者广播心跳时发现对方的日志落后,直接唤醒 replicator 的条件变量,让 replicator 异步的自行进行同步。
同步的时候,你不能 one by one 的发送,太慢了,比如你找到了 conflict index 和 conflict term,你可以一口气直接把属于在 conflict index 之后,又属于同一个 conflict term 的所有 log 一次性打包发送。当然你可以干脆直接把 conflict index 后面所有的日志都发了。
推进 commitIndex 时注意,你只能提交属于自己 term 的 log,论文里面讲的很清楚。我一开始没管这个,2B 也测不出来,到 2C 的时候就各种问题。
当你发现自己 2B 能稳定通过时,不要沾沾自喜自以为实现正确,实际上到了 2C 就会全部暴露出来。
2C Persistence
持久化这块不难,难的是你要你解决你在 2B 埋下的 BUG。
做持久化这块,只要你秉持一个观念:修改了 votedFor,log,logIndex,term 都需要立刻保存。当然后面搞了 snapshot,每一次修改 snapshot 也需要保存。
注意 TestFigure8Unreliable2C() 这个测试点,我就是在这个测试点上面卡了一星期。
2D Snapshot
Snapshot 这块我一开始有点没搞懂,论文里面说是当 raft 发现自身 log 太大时,自行进行 snapshot,但是 lab 里面的 snapshot 是被测试用例调用,后面弄了一大圈,才搞清楚逻辑。
上层的 service 发现 log 太大了(在 Lab2 中,由测试用例来充当 service),调用 snapshot 方法保存快照。
可以通过 rf.log[0] 来保存最新 snapshot 的 lastLogIndex,lastLogTerm 信息。
假设有一个节点一直是 crash 的,然后复活了,leader 发现其落后的太多,于是发送 InstallSnapshot() RPC 到落后的节点上面。落后节点收到 InstallSnapshot() 中的 snapshot 后,通过 rf.applyCh 发送给上层 service 。上层的 service 收到 snapshot 时,调用节点的 CondInstallSnapshot() 方法。节点如果在该 snapshot 之后有新的 commit,则拒绝安装此 snapshot,service 也会放弃本次安装。反之如果在该 snapshot 之后没有新的 commit,那么节点会安装此 snapshot 并返回 true,service 收到后也同步安装,有 2PC 的內味。
安装 snapshot 时不要忘记持久化。
Lab 3 KV Raft
这一节实验要求我们基于 raft 实现自己的 service,在这里 service 就是一个 K/V 数据库,然后由 client(也就是 clerk)和 service 进行交互,进行 CURD。
开始之前,我们可以参考 raft 作者的博士论文 Section 6,里面有讲到 client 和 service 交互的流程和 RPC 的设计。

Part A
在官方提供的代码骨架中,我们可以看到官方希望我们 Get、PutAppend 是分成两个 RPC 来做,这里我觉得没有必要,我把其合并在了一起,这样 service 那里也只需要一个方法就能处理 clerk 的所有请求。
Service 存储数据库直接用了一个 map 来替代,当然现实生活中肯定不是这么简单。
Service 端启动后会开启一个线程监听 applyMsg ,实时监听 raft 提交的 applyMsg,进行处理。所有的数据库操作都先通过 raft.Start() 提交操作,然后等到底层 raft apply 。
去重: 对 client 的请求去重非常的重要,6.824 里面也有说明,这里我通过 clientId 和 sequenceNum 这二元组确定唯一的请求。ClientId 由 clerk 被创建时随机生成,sequenceNum 初识值为 1,SequenceNum 只有在一条 command 执行成功后,才会 + 1。Service 那里也会使用一个 lastClientOperations map[int64]ClientOperation 结构来存储客户端最新的请求(注意是每一个节点都需要存储,而不只是 leader。不然 leader 挂了去重表也就丢失了。所以你需要 raft 传来 applyMsg 并成功执行 kv operation 后向去重表里面添加记录)。随着 client 的增多,lastClientOperations 肯定会变的很大,这里我没有管,没做处理,实验里面也不要求我们处理。具体的处理方法可以看博士论文。
注意:一个请求会经过两次去重检测,一次发生在 service 刚接收到来自 clerk 的 RPC,另一次在 service 收到从 raft 层传来的 applyMsg 准备开始写入数据库之前。
Part B
日志压缩我们注意一点,就是别忘记压缩用于去重的 lastClientOperations。
Lab 4 Sharded KV
Lab 4 要求我们实现一个 sharded K/V 数据库,相当于 multi-raft,也就是说一个 cluster 中运行多个 raft。传统的单一个 raft 集群因为只有一个 leader 负责与 client 交互,性能难免低下,我们可以对数据进行分片(取模最简单),比如 key 取模后为 1 的数据放在一个 replica group,2 的放在另外一个 group 中,这样能很好的分散请求到各个 group,同时让多个 raft leader 服务请求,解决 raft 性能低下的问题。
4A Shard Controller
实现 shard controller 比较简单,你可以直接从 Lab 3 copy 过来,甚至都不需要实现 snapshot,因为 config 变化的次数肯定很小,raft log 不会变的很大,没必要做 snapshot。
Shard controller 里面我们主要要解决一个 shard 平均分配到各个 group 的问题,这里我用的算法比较简单:用一个 for 循环,对应 join 操作:每一次从管理 shard 数量最多的 group 移一个 shard 到 shard 数量最少的 group;对应 leave 操作,则每次选择一个没人管的 shard 分配给管理 shard 数量最少的 group。当整个 config 中 $abs(maxShard-minShard)<=1$ 时,循环结束。
4B Shard K/V Server
这一块确实小复杂,我简单介绍下我的思路。
Clerk 这块没啥好说的,主要就是去重和分流到不同的 group,基本官方给的代码模板已经很清楚了。
主要还是 service 端,细节比较多:
独立的 shard:这里我的每一个 shard 都是独立的,然后每一个 shard 里面包含了一个存储数据的 map 和用户的去重表,所以每次转移 shard 时会带着去重表一起转移。且 shard 提供三种状态:serving,pulling 和 offering ,serving 则代表正常接收 clerk 请求,pulling 则代表该 shard 需要从其他 group 获取,offering 则表示该 shard 供远程 group 拉取。注意只有在 serving 时 shard 才会正常提供请求。
监控 config:Service 启动后,leader 会启动一个独立线程,持续的从 controller 读取当前 config 的下面一个 config。注意,不是获取最新的 config。比如你当前 config 是 2,那么你就获取 3,即使最新的 config 已经 10 了。这是因为我们的 config 变化要一步一步来,不能直接从 2 跳到 10,官方的 hints 里面也有提到。当获取到新的 config 时,对自己管理的 shard 进行标记(哪些 shard 能正常 serving,哪些 shard 则要 pulling 等等)。
注意只有当自己本地所有的 shard 为 serving 状态时,才能获取下一个 config。这很好理解,你这一步 config 下的 shard 都还没同步到位,怎么能开始变成下一个 config。
Shard 迁移:Shard 迁移我同样在 leader 中使用一个独立线程,leader 每隔一段时间扫描一次当前 group 的 shard(这里我是 50ms,不能太大,不然会 test fail),如果发现 shard 状态不为 serving,则开始迁移。(Shard 的状态变化由监控 config 的线程处理)
迁移时我们要知道 shard 从哪里来,到哪里去,所以我们实际上要保存两个 config,分别是当前的 config 和 上一个 config,这样我们就能获悉 shard 的来龙去脉。
迁移我采用的 push 的方式,即比如我发现我的 shard 2 是 offering,且要安装到另外一个 group,那么当前 group 发送一个 InstallShard() RPC 到另外一个 group,如果另外一个 group 成功接收且保存完毕(reply=OK),那么我就删除本地 shard,否则就当失败,等下一轮重新尝试 InstallShard(),直到成功。这么写相比于 pull 的方式,极大的减轻了工作量,而且顺带保证了能够及时 GC 无用的 shard。
Shard Insert, Delete:当我们需要安装一个新的 shard 或者删除一个 shard 时,请通过 raft.Start() 才操作,而不是直接本地删除。
注意监控 config 和 shard 迁移的线程只有 leader 才有,所以每一次循环执行时,请务必检查自己是不是 leader。同理,当一个节点成为 leader 时,你就要启动这两个线程。
活锁,提交空日志:考虑一种情况,一个节点刚成为 leader,但是 client 不提交请求,那么 raft 层就无法推进 commitIndex,使得节点无法同步,形成活锁。解决的办法很简单,就是另外弄一个线程实时监测 rf.log 中最新的数据是不是自己的 term,如果没有,则提交一个 empty entry 来推进整个 raft。
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/mit-6-824-notes
 微信扫一扫
微信扫一扫