2024 年的今天,从事实上看,Parquet 貌似已经在这一场数据湖格式之争中胜利了,这从各大表格式的支持程度上可见一般。
| Hudi | Paimon | Iceberg | DeltaLake | Hive | |
|---|---|---|---|---|---|
| Parquet | ✅ | ✅ | ✅ | ✅ | ✅ |
| ORC | ❌ | ✅ | ✅ | ❌ | ✅ |
本文存粹按照个人的理解,记录下两种格式的区别,不做任何评判。如果错误,欢迎评论。
文件结构
ORC 和 Parquet 两种格式都是按列存储,且在复杂类型上,存储的都是最后打平的子列。比如 col1 STRUCT<a: int, b: int>,文件最后实际存储的只有 col1.a 和 col1.b 两个 Int 子列。
ORC
ORC 元信息使用 ProtoBuf 压缩,其 proto 文件 GitHub 里面没有,故我上传到了 gist 上,便于查阅:https://gist.github.com/Smith-Cruise/d016ab9d7c9fa2e4a6e4dc0ed569b1a7
------ Stripe 1 ------
[Index Data]
[Row Data]
[Stripe Footer]
------ Stripe 1 ------
------ Stripe N ------
[Index Data]
[Row Data]
[Stripe Footer]
------ Stripe N ------
------ Tail ------
[Metadata]
[Footer]
[PostScript]
[1 byte PostScript length]
------ Tail ------一个 ORC 文件由一个 Tail 和多个 Stripe 组成。
Stripe:
- 每个 Stripe 之间互相独立,Stripe 由 Index Data,Row Data 和 Stripe Footer 三部分组成。
- Index Data 和 Row Data 由若干个 Stream 组成,Stream 有很多种类型,具体见官方文档。
- Stripe Footer 里面存储着 Index Data 和 Row Data 中每一个 Stream 的 offset/length,不含列的统计信息。
- Stripe 中的每一列会被划分成多个 Row Group,每一个 Row Group 默认是 10000 行。Row Group 是 ORC 的最小读取单元,每一个 Row Group 都有其对应的统计信息,存放在 Index Data 中。
Tail:
- Metadata:存储每个 Stripe 中每一列的统计信息。
- Footer :存储每个 Stripe 的元信息,如行数,offset 以及 length 等。
- PostScript:描述 Footer 和 Metadata 的 offset 以及 length。
- 1 byte PostScript length:描述 PostScript 的长度。
Reader 的读取路径分为两种:
开启 SearchArgument 谓词下推:[1 byte PostScript length] → [PostScript] → [Footer] → [Metadata] → [StripeFooter] → [RowIndex] → [RowData] 。
没有谓词下推:[1 byte PostScript length] → [PostScript] → [Footer] → [StripeFooter] → [RowData] 。
Parquet
Parquet 元信息使用 thrift 序列化,thrift 结构见:https://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift
------ Row Group 1 ------
[ColumnChunk]
------ Row Group 1 ------
------ Row Group N ------
[ColumnChunk]
------ Row Group N ------
------ Tail ------
[FileMetadata]
[4 byte FileMetadata length]
------ Tail ------Parquet 由多个 RowGroup 和一个 FileMetadata 组成。
Row Group:
每一个 Row Group 都是独立的单元,但是它是没有所谓的 Row Group Footer。Row Group 里面的每一列是一个 ColumnChunk。
ColumnChunk:
ColumnChunk 划分成 required,optional 和 repeated 三种:
- Required:用于表示非 nullable 列。
- Optional:用于表示 nullable 列。
- Repeated:用于表示数组。
Page:
ColumnChunk 会被划分成多个 Page,每一个 Page 都有一个 PageHeader 和实际的数据,Page 是 Parquet 的最小读取单元。
PageHeader 存储该 Page 的 definition level 和 repetition level,当然不是说一定有 def/rep level。如果这一列是 required 的,那么 def level 就不存在。如果这一列不是 array,那么 rep level 就不存在。
FileMetadata:
存放了每个 Row Group 及其 ColumnChunk 的元信息和统计信息。这是因为 Row Group 是没有 footer 结构来承担该 Row Group 中的元信息 ,所以 FileMetadata 就承担了整个文件的所有元信息。
两者对比
列个表格,把 ORC 和 Parquet 等价的概念放一起。
| ORC | Parquet | 说明 |
|---|---|---|
| Footer+Metadata | FileMetadata | 描述每一个 Stripe/RowGroup 的元信息和统计信息。 |
| Stripe | Row Group | Stripe 有一个 StripeFooter,而 Row Group 没有。 |
| Row Group | Page | 都是最小的读取单位。 |
类型系统
ORC
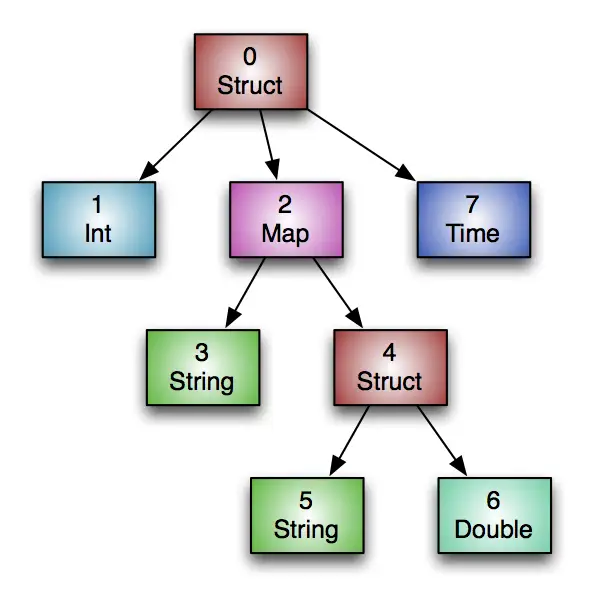
ORC 的类型很直观,每一个文件只有一个类型 root type,是一个 StructColumn,然后下面会挂着很多子类型。
比如一张表是 col1: STRING, col2: INT, col3: MAP<INT, INT>,那么 ORC 文件中的类型是 STRUCT<col1: STRING, col2: INT, col3: MAP<INT, INT>>。
如下图,ORC 每列都有一个 ColumnId,但是它是不会写在 proto 文件里面,而是通过代码按照先序遍历赋值,所以 root 类型 StructColumn 的 ColumnId 永远是 0。

Parquet
Parquet 类型分为 physical type 和 logic type。Physical type 犹如构建这个世界的基础元素金木水火土,logic type 则是世间万物。
Physical type 指列实际存储二进制的类型,有 INT32,INT64,BYTE_ARRAY 等一些编程语言都有的基础类型。
Logic type 构建于 physical type 之上,好比在 physical type 上面加点元信息,用于表达更加复杂的类型,比如 TIMESTAMP,DATE,DECIMAL 这些。像 String 是基于 BYTE_ARRAY 实现,DATE 是基于 INT32 实现。
在复杂类型上面,Parquet 使用 def/rep level 来处理。Def level 表达嵌套类型的层级,rep level 表示 array 的元素划分。
两者对比
ORC 没啥好说的,它的设计符合一个普通人的正常想法,没什么特别的。
Parquet physical type + logical type 的组合在代码实现上可以玩的很骚。对于读取 Parquet 的二进制数据来说,我只需要实现一个 PhysicalColumnReader 就行了。因为 physical type 不多,所以不用实现很多种 ColumnReader。然后再实现一个 LogicalColumnConverter 用于把数据从 physical type 转换成对应的 logic type。
这样就相当于把繁杂缤纷的 logic type 和实际二进制存储的 physical type 给解耦开来了。将来扩展类型也很方便,只需要在 logical type 上面进行扩充就行了,physical type 则不用动。
同时 def/rep levels 的引入,让复杂类型的表达更加高效。比如想表达一列 nullable 的 array,其每一个 element 也是 nullable 的,可以用如下三层结构清晰表达:
optional group list (LIST) {
repeated group list {
optional INT_64 element;
}
}不过玩的这么花坏处也显而易见,你去看看 Parquet logic type 的标准,一堆 deprecated 的历史包袱,这让开发 reader 的人在兼容性问题上很是头疼。同时 def/rep levels 的天才设计,也是 reader 里面 bug 的重灾区。相反 ORC 简洁明了的类型系统,就没那么麻烦了。
NULL 的处理
Parquet 用 def level 处理了 null 的表示。ORC 则中规中矩的用一个 null 数组表示。
两者对于 null 的一行,都不会真实的存储数据,例子如下:
实际二进制数据: [1, 3, 5]
null 信息: [false, true, false, true, false]
翻译后: [1, null, 3, null, 5]复杂类型存储
ORC 采用了直白的层层嵌套来管理复杂类型,Parquet 则采用 def/rep levels 表达嵌套类型。
ORC:
在读取的时候,ORC 设计的弊端就非常明显。
比如一列类型是:col1: STRCUT<a: STRUCT<b: int>>
ORC reader 中你需要创建出一个四层嵌套的 Reader( root 节点是 struct,也得算进去,所以有四层):
StructColumnReader(root) {
StructColumnReader(col1) {
StructColumnReader(a) {
IntColumnReader(b)
}
}
}每一层都有其对应的 null 需要处理,在上面这个例子中,你需要读取 4 个 null 数组。Null 数组都是用 RLE 压缩过的 0 和 1,decode 也是需要一定的 CPU。此外四层 reader 的虚函数调用也得考虑一下。很明显,嵌套层级越深,读取的开销就会越大。
此外在物理数据的分布上,ORC 的设计会带来严重的离散 IO,下面来一个复杂点的例子,假设一个 ORC 文件类型如下,我在每一列上面标注了 ColumnId:
Root(0): STRUCT {
col1(1): INT,
col2(2): STRUCT {
a(3): INT,
b(4): INT
},
col3(5): INT
}按照 ORC 的文件结构,Stripe 中 Stream 的编排如下:
[RowIndex 0]
[RowIndex 1]
[RowIndex 2]
[RowIndex 3]
[RowIndex 4]
[RowIndex 5]
[Present 0]
[Present 1]
[RowData 1]
[Present 2]
[Present 3]
[RowData 3]
[Present 4]
[RowData 4]
[Present 5]
[RowData 5]Present 是表示 null 的 Stream,Struct 列是没有 RowData 的,但是会有 RowIndex 和 Present 的。
假设我们只读取 col2.a 子列,意味着需要加载 ColumnId = [0,2,3] 的数据:
[RowIndex 0] [Read]
[RowIndex 1]
[RowIndex 2] [Read]
[RowIndex 3] [Read]
[RowIndex 4]
[RowIndex 5]
[Present 0] [Read]
[Present 1]
[RowData 1]
[Present 2] [Read]
[Present 3] [Read]
[RowData 3] [Read]
[Present 4]
[RowData 4]
[Present 5]
[RowData 5]这离散的 IO 不用我说了吧。这也是为什么 Presto/Trino 它们搞了一个 tiny stripe 的优化,因为这种情况在 stripe 小的情况下会更严重。Stripe 小,意味着每一个 Stream 一定都不大,但是它们的分布又不是连续的(比如要读取的 Stream 之间都间隔个几 KB),这会搞得 IOPS 很大。对于这种情况,不如直接把整个 Stripe 拉下来省事。
Parquet:
而 Parquet 就不会有这个问题,它可以直接根据子列的 def/rep levels 直接还原出整个嵌套结构。
比如还是 col1: STRCUT<a: STRUCT<b: int>> 这个例子,我们直接创建一个 IntColumnReader 读取就行了,之后根据 def/rep levels 还原成一个 struct,这样也有效避免了虚函数调用。
不过目前貌似没有 reader 是这么实现的,大家还是会创建层层包裹的 ColumnReader。这么做一方面是代码结构上清晰易懂,另一方面是大家建表的时候,struct 嵌套的层数普遍不会很深,所以那点虚函数调用,也无所谓。
不过倒是只要读取一次 null 就好了。
小结:
两者本质上的区别就是,ORC 的子列还是会和其父节点产生关联(null 数组/统计信息),而 Parquet 子列根本就没有父亲节点,子列完全独立,其根据自身存储的 def/rep levels 就可以直接复原整个结构。
统计信息
ORC 和 Parquet 的统计信息都能精确到 Row Group/Page 上面,唯独区别就是统计信息存放位置不同罢了。
ORC 的统计信息分成如下三个级别:
- FileStatistics:文件级别每一列的统计信息,存在 Footer 上。
- StripeStatistics:Stripe 级别每一列的统计信息,存放在文件末尾的 Metadata 上。
- RowIndex:Row Group 级别每一列的统计信息,存放在 Stripe 的开头 Row Index 部分。
Parquet 统计信息只简单的分成 Row Group 和 Page 两个级别,没有文件级别的统计信息:
- ColumnMetadata#Statistics:RowGroup 中每一列的统计信息,放在 FileMetadata 里面。
- PageHeader#Statistics:每一个 Page 的统计信息,存放在对应 Page 的 header。
ORC 的统计信息分布零散,而 Parquet 相对简单粗暴,基本直接全塞 FileMetadata 里面。
不过 Parquet Page 级别的统计信息其实比较鸡肋,因为你读取 PageHeader 的时候,因为上层应用的 IO 合并,IO 对齐等优化,你大概率会把 PageData 的数据也读了过来。此时你 PageHeader 就算过滤掉又能如何?PageData 的数据拉都拉过来了,无非就是省了一个 decode 的过程。
当然 Parquet 自身也意识到了这个问题,搞了一个 PageIndex,你可以简单的认为把 ColumnChunk 中所有 Page 的统计信息汇总在一个地方,而不是零散在每一个 Page 的 header 上面。PageIndex 的信息通常都是写在 FileMetadata 的上面。
随机 IO
在上面的介绍中,你可以发现 ORC 的统计信息、null,Data 的存放相较于 Parquet 来说,更为零散,所以更容易导致随机 IO。
而 Parquet 一股脑的把绝大多数的元信息都塞在 FileMetadata 中,同时又通过 PageIndex 把所有 page 的统计信息都汇总在一个地方,这极大的缓解随机 IO 的情况。
Footer 的大小
因为 ORC 的 footer 有文件级别和 Stripe 两个级别,所以其文件的 footer 不是很大,这样带来的 proto 反序列化开销就还好。
但是 Parquet 因为一股脑的全塞 FileMetadata,这导致了 Parquet 的 footer 不可避免的大,这会带来很大的反序列化开销。而且貌似 Thrift 的性能其实是比 Protobuf 差的?
可能大家觉得还好,其实不然。现代 OLAP 系统,都会把一个文件按照 Stripe/Row Group 拆碎成多个 split,然后分发到不同的机器上面并发执行。对于 ORC 和 Parquet 来说,footer 是每一个 split 都必须要读取的。比如一个文件你拆成 5 个 split 分发到 5 个机器上面,那你的 footer 就要被重复读取 5 次。此时如果 footer 很大,那多次反序列化带来的 CPU,网络开销是不可忽略的。毕竟我有幸见过光 footer 就有 100~200 mb 的 Parquet 文件。
Schema Evolution
这年头,湖格式都支持 schema evolution。Schema evolution 都是轻量的,基于元信息的修改,但是实现的前提就是每一列都需要绑定一个唯一且独立的 id。
此时 ORC 有一个很要命的地方,就是它的子列是没有唯一的独立 id,这给 schema evolution 的实现上带来的很大的困难。它虽然有一个 ColumnId 的概念,但是那是代码先序遍历推导出来的,并没有记录在其 proto 文件中。
当然不是说 ORC 就不能 schema evolution 了,比如 Iceberg 会把 ORC 的列和 id 映射关系以 map 的形式存储在 ORC 的 properties 里面,存粹就是恶心一下实现 reader 的人罢了。
Parquet 则直接在 thrift 里面定义了列的 field_id 属性,那就能很好的和 schema evolution 配合在一起了。
Offset 的灵活性
关注 parquet thrift 的结构定义,你会发现 parquet 对于一个 struct 存放位置描述,往往都是以 offset/length 的形式处理。比如 PageIndex 在哪里,弄个 offset 和 length 给你,然后你自己去读那个位置。再比如 ColumnMetadata 里面各种 page 的位置,给的也是一个 offset。这样有个好处就可以给 write 更加灵活的操作空间。比如 PageIndex 我即可以写文件的开头,也可以写文件末尾,随意。而且将来也能有更好的兼容性。
反观 ORC 的结构,其基本已经定死了,比如 Stripe 中 index 部分一定在 data 前面,等等。你基本上可以通过 protobuf 来倒推出整个 ORC 文件的结构。
总的来说这个也没啥把,毕竟性能上也带不来什么优势,无非就是 parquet 可以方便反悔某个模块在文件中的位置。
结束语
深夜和女朋友干架,就先写到这,以后有新的见解,再补充吧。
原创文章,作者:Smith,如若转载,请注明出处:https://www.inlighting.org/archives/orc-vs-parquet-who-is-best
 微信扫一扫
微信扫一扫
评论列表(4条)
NB 写的真好 顺便细说干架
@mxdzs0612: 我这个人不记仇,已经忘了。
我这个人不记仇,已经忘了。
nbnb!
@letian:💪我会努力的